Introduction
Earlier this year, we here at InQuest launched our new InQuest Labs website. Labs is an amazing resource, with a plethora of useful tools and intelligence offerings. Much could be written about the site, and much has been…but not about this part right here:
What is the “Base64 Regular Expression Generator”? What is “Base64”? What’s a “Regular Expression”? What’s a “Generator”?
Okay, you probably know the answer to all of those questions (and if not, that’s okay, we’ll cover the answers cursorily here), but you may not know what all those words mean in that particular order.
The short version is that the Base64 Regular Expression Generator (or “b64re” for short) is a tool that, given a regular expression, will give you a new regular expression that matches what the first expression would’ve matched if its input were Base64-encoded.
This sounds simple (or maybe it doesn’t), but it’s actually more complex than you might think. To understand why, and the motivation behind it, let’s look at why we have Base64 in the first place.
The Origins of Base64
(You can skip this part if you know about Base64, but there’s a fun part about old networks and the history of telecommunications you might enjoy.)
Long, long ago, in that ancient time known as “1987”, when the greatest computing platform of all time was only two years old, email was starting to become mainstream, and people started wondering about how to make it better.
Email back then (or “e-mail” or “electronic mail” as it was more often known back then before brevity was a thing) was already an established technology, but one with a multitude of implementations.
This variety in implementations was subject then to Postel’s Law: “be conservative in what you do, liberal in what you receive.”
The idea was that you should do the minimum you needed to do to get a message delivered because the other side with whom you’re communicating might not support all the extensions you did. On the other hand, you should accept reasonable mistakes from people communicating with you. If these rules are followed, more communications happen, and more people are happy.
Well, one of the things that not everyone could do back then was send eight bits at a time. You heard me right.
In 1987 (and well into the 1990’s), many communications links might only have supported sending a mere seven bits at a time.
This might sound surprising, but recall that even our beloved ASCII is only a seven-bit specification. Communications links still often spoke in units of eight bits on the wire, but the eighth bit might be used for parity checking, bit robbing, metainformation, or any other use. In other words, by Postel’s Law, you couldn’t assume that everyone you spoke to could handle eight-bit bytes.
You couldn’t even assume the eighth bit was always zero: some old systems, like Pr1me systems, would have the eighth bit set instead of clear. It made life interesting.
Anyway, the point is, you couldn’t assume that you could get eight-bit bytes. For things like ASCII text this wasn’t a problem because ASCII could be safely transmitted in seven bits.
But for things like binary files (and, I don’t know, languages written in things other than the basic English alphabet plus a few symbols, used by billions and billions of people) it wouldn’t work. (Note: I know that Unicode first required sixteen bits for a raw codepoint and now requires 21 bits, but work with me here.)
So, there was a conundrum: some communications links only supported seven-bit transmission, but the need existed to transmit eight-bit data. Various encoding schemes were created to support this, but Base64 enters the story with the advent of Privacy Enhanced Email in 1987.
Privacy Enhanced Email (I’m avoiding using the acronym for obvious reasons) supported encrypting email. This was absolutely fantastic, but ran into the problem that most encryption algorithms are designed to work with eight-bit bytes, and since mail couldn’t assume an eight-bit-clean-channel…well, you can see where this is going.
Base64 was proposed as an efficient mechanism to encode eight-bit bytes using seven-bits per character or fewer. It did this by using a base 64 symbol system (that is, 64 distinct symbols; contrast this with “base 10” numerals that have 10 (0-9) distinct symbols). Base64 differed from earlier systems in that the 64 symbols chosen were less likely to cause problems in other situations.
Earlier binary-to-text encoding mechanisms had included problematic characters like whitespace, backtick, parentheses, and so on: things that, when read elsewhere, might have been interpreted differently. Base64 kept it safe with just upper- and lower-case ASCII alphabetic characters, decimal digits, and the “/” and “=” characters.
Base64 is “efficient” in that it only (“only”) results in a 33% increase in the size of the encoded data: three eight-bit bytes are encoded into four characters. Other, more efficient, encodings into seven-bit-ASCII-safe characters are possible (e.g., Ascii85, but they all can result in “problematic characters” in the encoded output. So, long story short (too late!): Base64 has become the de facto standard in encoding binary data in places where text is required or expected.
Security Implications of Base64 Encoding
Because of its ubiquity, Base64 has become the de facto standard for encoding of binary data in text-centric areas.
Its widespread support means that it’s also a popular and trivial obfuscation technique for malicious payloads. Almost every language has a Base64 codec in its standard library, and tools to manipulate the format are ubiquitous.
That’s where b64re comes into play: what if you want to find that encoded malicious payload inside a binary blob? Or on the wire? Or in the cells of an Excel spreadsheet?
Well, one thing you can do is extract all the salient content of a structured file and scan it, but that doesn’t always work for hunting and carving. If you run into a file that is, as far as you can tell, a blob of bytes (or random text), it might still be nice to see if any of your known-evil payloads are in there.
b64re lets you do that by taking your existing regular expressions and transforming them into a new regular expression that will find what you’re looking for. As an immediate real-world valuable example, consider that PowerShell accepts Base64 encoded arguments, and this feature is heavily (ab)used by attackers. Our generated Base64_Encoded_PowerShell_Directives YARA rule (relevant blog) can alert on encoded PowerShell on transit. Let’s dive into how one would go about writing a generator.
It’s Harder Than It Looks
Base64 encoding is simple, and matching regular expressions is simple, but getting the two to mix is problematic.
The problem is that when encoded, the bits of one byte of the input might be mixed into multiple bytes in the output. Losing this one-to-one correspondence means that you can’t just encode every component of a regex and be done with it: what happens when a regex component matches a variable-length string?
Problems
Problems are what happens.
Let’s take a simple example and see how it looks. Take this regex: hello, world! and encode it using b64re^1^:
$ curl "https://labs.inquest.net/api/yara/base64re?instring=hello%2C%20world!"And here’s what we get back:
([x2bx2f-9A-Za-z][2GWm]hlbGxvLCB3b3JsZC[E-H]|aGVsbG8sIHdvcmxkI[Q-Za-f]|[x2bx2f-9A-Za-z]{2}[159BFJNRVZdhlptx]oZWxsbywgd29ybGQh)Already, you can see that things have gotten complicated, even with a static string as input: there are alternations, some character classes, a bit of repetition, and so on. Why is that?
Well, recall from the description above (in the section that was marked optional above but was in fact apparently not) that Base64 expands three bytes of input into four bytes of output. That means that the encoding of a given byte is going to depend on its position in the input mod 3. Astute readers may note that the output regex above has three branches for this reason: the same input is encoded three times, once for each possible offset modulo three. With that expansion of three bytes to four, bits of bytes get mixed. A single byte can be split, and its first or last one or two bits can be mixed with the preceding or following bytes.
This commingling of bits is the hardest part of the whole process. For example, a literal byte followed by a character class: a[bcd] has to account for the last bits of a being the first bits of b, c, or d (readers who know off the tops of their heads that b, c, and d all have the same first bits in ASCII just be quiet for a minute).
This is compounded when you add alternations into the mix: a([bcd]|[efg]|[hij]) Now you have this combinatoric explosion of potential first bits. And don’t even get me started on the match-anything dot!
The biggest problem, though,is the star * (or, for you, formal automata fans out there, the Kleene closure): This operator matches zero or more instances of the preceding expression.
In other words: ab(cd)*ef matches
abef
abcdef
abcdcdef
abcdcdcdefand so on, for any number of cd‘s in the middle there. Don’t forget that the modulo-three rule applies here as well.
The Result
The point of all this is that the InQuest Labs Base64 Regular Expression Generator Tool does a lot of hard work so that you don’t have to.
To make it obvious, let’s look at a practical example. Microsoft PowerShell supports the -EncodedCommand flag. This useful flag lets you pass a Base64-encoded PowerShell command as an argument, which will then be decoded and executed.
You can see where this is going. PowerShell commands might be embedded inside an Office document, and Base64 encoded for the sake of obfuscation. The encoded command might even be padded on either side with valid Base64 characters, with the pivot pulling out just the substring needed to decode for the payload.
Given this, the it would be great if we could simply look through the whole file for Base64-encoded string Start-Process -filePath "calc.exe"
How would that look, Base64-encoded? Well, let’s run it through the InQuest Labs API:
$ curl "https://labs.inquest.net/api/yara/base64re?instring=Start-Process%20-filePath%20%22calc.exe%22"And our result looks like this (de-JSONified):
([x2bx2f-9A-Za-z]{2}[159BFJNRVZdhlptx]TdGFydC1Qcm9jZXNzIC1maWxlUGF0aCAiY2FsY[x2bx2f-9w-z]
[159BFJNRVZdhlptx]leGUi|U3RhcnQtUHJvY2VzcyAtZmlsZVBhdGg{2}ImNhbG[M-P][x2bx2f-9A-Za-z]ZXhlI[
g-v]|[x2bx2f-9A-Za-z][1FVl]N0YXJ0LVByb2Nlc3MgLWZpbGVQYXRoICJjYWxj[x2bx2f-9A-Za-z][2GWm]V4
ZS[I-L])So, that’s a bit verbose, but we can confirm it works with a little Python:
$ python
>>> import base64
>>> encoded = base64.b64encode('Start-Process -filePath "calc.exe"')
>>> encoded
'U3RhcnQtUHJvY2VzcyAtZmlsZVBhdGggImNhbGMuZXhlIg=='
>>> import re
>>> re.match(r"""([x2bx2f-9A-Za-z]{2}[159BFJNRVZdhlptx]TdGFydC1Qcm9jZXNzIC1maW
xlUGF0aCAiY2FsY[x2bx2f-9w-z][159BFJNRVZdhlptx]leGUi|U3RhcnQtUHJvY2VzcyAtZmlsZV
BhdGg{2}ImNhbG[M-P][x2bx2f-9A-Za-z]ZXhlI[g-v]|[x2bx2f-9A-Za-z][1FVl]N0YXJ0LV
Byb2Nlc3MgLWZpbGVQYXRoICJjYWxj[x2bx2f-9A-Za-z][2GWm]V4ZS[I-L])""", encoded)
<_sre.SRE_Match object at 0x7fd66be3e5d0>I realize that doesn’t look like much, but the fact that re.match returned a Match object means that it worked! We found our malicious invocation of the calculator. To go a bit further, let’s try finding a non-malicious invocation of Notepad:
>>> encoded = base64.b64encode('Start-Process -filePath "notepad.exe"')
>>> re.match(r"""([x2bx2f-9A-Za-z]{2}[159BFJNRVZdhlptx]TdGFydC1Qcm9jZXNzIC1maW
xlUGF0aCAiY2FsY[x2bx2f-9w-z][159BFJNRVZdhlptx]leGUi|U3RhcnQtUHJvY2VzcyAtZmlsZV
BhdGg{2}ImNhbG[M-P][x2bx2f-9A-Za-z]ZXhlI[g-v]|[x2bx2f-9A-Za-z][1FVl]N0YXJ0LV
Byb2Nlc3MgLWZpbGVQYXRoICJjYWxj[x2bx2f-9A-Za-z][2GWm]V4ZS[I-L])""", encoded)
>>>This is interesting: the regular expression didn’t match, and we avoided a false-positive!
Obfuscation
But, still, in the examples above, we’re just encoding a static string. What if our attackers are smart? What if they obfuscate their malicious payload? Let’s think about how we can obfuscate the payload above (slightly simplified for the sake of space): Start-Process "calc.exe" Might be written as start-process "calc.exe" or even sTaRt-PrOcEsS 'calc.exe' that is, with a bunch of extra space and case flipping. That’s where regular expressions, and b64re, come into play.
I know that you might not enjoy writing regular expressions like I do, so I’ll just cut to the chase and say that this regular expression will catch a fair amount of obfuscation in the string above:
[Ss][Tt][Aa][Rr][Tt]-[Pp][Rr][Oo][Cc][Ee][Ss]{2}[ t]+["']calc.exe['"'] (you sticklers out there can point out in the comments all the obfuscations I missed, I know, I know).
Let’s see what this beautiful bit of regex-fu turns into when Base64 encoded:
$ curl "https://labs.inquest.net/api/yara/base64re?instring=%5BSs%5D%5BTt%5D%5BAa%5D%5BRr%5D%5BTt%5D-%5BPp%5D%5BRr%5D%5BOo%5D%5BCc%5D%5BEe%5D%5BSs%5D%7B2%7D%5B%20%5Ct%5D%2B%5B%22'%5Dcalc.exe%5B'%22'%5D"And the result is:
([Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][02]V[Tz][Uc][wy][Ak][in]Y2Fs
Y[+/-9w-z][159BFJNRVZdhlptx]leGU[in]|[+/-9A-Za-z]{2}[159BFJNRVZdhlptx]
[Tz][Vd][EG]F[Sy][Vd]C1[Qw][Uc][km]9[Dj][RZ][VX]N[Tz][CI]([048ACEIMQSU
Ycgikoswy]|[+/-9A-Za-z][CI])*[048AEIMQUYcgkosw][Jg][IJ][2m]NhbG[M-P][+
/-9A-Za-z]ZXhl[IJ][+/-9g-z]|[Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][0
2]V[Tz][Uc][wy]([048ACEIMQSUYcgikoswy]|[+/-9A-Za-z][CI])*[ACQSgiwy][Ak
][in]Y2FsY[+/-9w-z][159BFJNRVZdhlptx]leGU[in]|[+/-9A-Za-z]{2}[159BFJNR
VZdhlptx][Tz][Vd][EG]F[Sy][Vd]C1[Qw][Uc][km]9[Dj][RZ][VX]N[Tz][CI]([04
8ACEIMQSUYcgikoswy]|[+/-9A-Za-z][CI])*[CI][CS][Jd]jYWxj[+/-9A-Za-z][2G
Wm]V4ZS[I-Lc-f]|[+/-9A-Za-z][13FHVXln]N[0U][QY][VX]J[0U]L[VX]B[Sy][Tb]
[02]N[Fl][Uc][13]M[Jg]([048ACEIMQSUYcgikoswy]|[+/-9A-Za-z][CI])*[ACQSg
iwy][Ak][in]Y2FsY[+/-9w-z][159BFJNRVZdhlptx]leGU[in]|[+/-9A-Za-z][13FH
VXln]N[0U][QY][VX]J[0U]L[VX]B[Sy][Tb][02]N[Fl][Uc][13]M[Jg][CI][CS][Jd
]jYWxj[+/-9A-Za-z][2GWm]V4ZS[I-Lc-f]|[+/-9A-Za-z][13FHVXln]N[0U][QY][V
X]J[0U]L[VX]B[Sy][Tb][02]N[Fl][Uc][13]M[Jg][CI][CS][Jd]jYWxj[+/-9A-Za-
z][2GWm]V4ZS[I-Lc-f]|[+/-9A-Za-z][13FHVXln]N[0U][QY][VX]J[0U]L[VX]B[Sy
][Tb][02]N[Fl][Uc][13]M[Jg][CI][CS][Jd]jYWxj[+/-9A-Za-z][2GWm]V4ZS[I-L
c-f]|[+/-9A-Za-z]{2}[159BFJNRVZdhlptx][Tz][Vd][EG]F[Sy][Vd]C1[Qw][Uc][
km]9[Dj][RZ][VX]N[Tz][CI]([048ACEIMQSUYcgikoswy]|[+/-9A-Za-z][CI])*[AC
QSgiwy][Ak][in]Y2FsY[+/-9w-z][159BFJNRVZdhlptx]leGU[in]|[+/-9A-Za-z][1
3FHVXln]N[0U][QY][VX]J[0U]L[VX]B[Sy][Tb][02]N[Fl][Uc][13]M[Jg][CI][CS]
[Jd]jYWxj[+/-9A-Za-z][2GWm]V4ZS[I-Lc-f]|[+/-9A-Za-z][13FHVXln]N[0U][QY
][VX]J[0U]L[VX]B[Sy][Tb][02]N[Fl][Uc][13]M[Jg][CI][CS][Jd]jYWxj[+/-9A-
Za-z][2GWm]V4ZS[I-Lc-f]|[+/-9A-Za-z][13FHVXln]N[0U][QY][VX]J[0U]L[VX]B
[Sy][Tb][02]N[Fl][Uc][13]M[Jg]([048ACEIMQSUYcgikoswy]|[+/-9A-Za-z][CI]
)*[+/-9A-Za-z][CI][CS][Jd]jYWxj[+/-9A-Za-z][2GWm]V4ZS[I-Lc-f]|[Uc][13]
R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][02]V[Tz][Uc][wy][Ak][Jg][IJ][2m]NhbG[
M-P][+/-9A-Za-z]ZXhl[IJ][+/-9g-z]|[Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv]
[QY][02]V[Tz][Uc][wy][Ak][Jg][IJ][2m]NhbG[M-P][+/-9A-Za-z]ZXhl[IJ][+/-
9g-z]|[+/-9A-Za-z]{2}[159BFJNRVZdhlptx][Tz][Vd][EG]F[Sy][Vd]C1[Qw][Uc]
[km]9[Dj][RZ][VX]N[Tz][CI][CS][Jd]jYWxj[+/-9A-Za-z][2GWm]V4ZS[I-Lc-f]|
[Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][02]V[Tz][Uc][wy][Ak][Jg][IJ][
2m]NhbG[M-P][+/-9A-Za-z]ZXhl[IJ][+/-9g-z]|[Uc][13]R[Bh][Uc][ln]Qt[Uc][
FH]J[Pv][QY][02]V[Tz][Uc][wy][Ak][Jg][IJ][2m]NhbG[M-P][+/-9A-Za-z]ZXhl
[IJ][+/-9g-z]|[+/-9A-Za-z]{2}[159BFJNRVZdhlptx][Tz][Vd][EG]F[Sy][Vd]C1
[Qw][Uc][km]9[Dj][RZ][VX]N[Tz][CI][ACQS][Ak][in]Y2FsY[+/-9w-z][159BFJN
RVZdhlptx]leGU[in]|[Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][02]V[Tz][U
c][wy][Ak][Jg][IJ][2m]NhbG[M-P][+/-9A-Za-z]ZXhl[IJ][+/-9g-z]|[+/-9A-Za
-z][13FHVXln]N[0U][QY][VX]J[0U]L[VX]B[Sy][Tb][02]N[Fl][Uc][13]M[Jg]([0
48ACEIMQSUYcgikoswy]|[+/-9A-Za-z][CI])*[CI][CS][Jd]jYWxj[+/-9A-Za-z][2
GWm]V4ZS[I-Lc-f]|[+/-9A-Za-z]{2}[159BFJNRVZdhlptx][Tz][Vd][EG]F[Sy][Vd
]C1[Qw][Uc][km]9[Dj][RZ][VX]N[Tz][CI]([048ACEIMQSUYcgikoswy]|[+/-9A-Za
-z][CI])*[+/-9A-Za-z][CI][CS][Jd]jYWxj[+/-9A-Za-z][2GWm]V4ZS[I-Lc-f]|[
Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][02]V[Tz][Uc][wy]([048ACEIMQSUY
cgikoswy]|[+/-9A-Za-z][CI])*[CI][CS][Jd]jYWxj[+/-9A-Za-z][2GWm]V4ZS[I-
Lc-f]|[Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][02]V[Tz][Uc][wy]([048AC
EIMQSUYcgikoswy]|[+/-9A-Za-z][CI])*[048AEIMQUYcgkosw][Jg][IJ][2m]NhbG[
M-P][+/-9A-Za-z]ZXhl[IJ][+/-9g-z]|[+/-9A-Za-z][13FHVXln]N[0U][QY][VX]J
[0U]L[VX]B[Sy][Tb][02]N[Fl][Uc][13]M[Jg]([048ACEIMQSUYcgikoswy]|[+/-9A
-Za-z][CI])*[048AEIMQUYcgkosw][Jg][IJ][2m]NhbG[M-P][+/-9A-Za-z]ZXhl[IJ
][+/-9g-z]|[Uc][13]R[Bh][Uc][ln]Qt[Uc][FH]J[Pv][QY][02]V[Tz][Uc][wy]([
048ACEIMQSUYcgikoswy]|[+/-9A-Za-z][CI])*[+/-9A-Za-z][CI][CS][Jd]jYWxj[
+/-9A-Za-z][2GWm]V4ZS[I-Lc-f]|[+/-9A-Za-z][13FHVXln]N[0U][QY][VX]J[0U]
L[VX]B[Sy][Tb][02]N[Fl][Uc][13]M[Jg][IJ][2m]NhbG[M-P][+/-9A-Za-z]ZXhl[
IJ][+/-9g-z])Now, aren’t you glad you didn’t have to write all that yourself?
Endianness
Note that some forms of difference in the strings you’re looking for might not be for the purposes of obfuscation: they might just be how strings are stored.
Remember when I mentioned earlier that Unicode used to need 16 bits to represent a raw codepoint? Well, a lot of times, characters will be stored in two bytes precisely for this reason. (Remember when I also said that now Unicode needs 21 bits to represent a code point? Don’t get me started on how the common two-byte encodings deal with that…) So, that raises a question: if a character is stored in two bytes, how are the bytes ordered?
Do you transmit the most-significant byte first, or second? In other words, should the codepoint 0x235D (⍝ APL FUNCTIONAL SYMBOL UP SHOE JOT)^2^ be stored as the bytes {0x23, 0x5d} or as {0x5d, 0x23}?
The answer is, well, it depends. Some systems default to one ordering and some to the other Unicode provides a way to indicate which ordering a document is using, but that is often omitted.
(For more fun reading, it’s interesting to point out that different processors order multi-byte values in different ways. Intel processors generally use little-endian, meaning that the least-significant byte is stored first. The best processor architecture ever was big-endian, meaning it stores the most-significant byte first. Some processors can be switched at boot, or even at runtime, between the two endianness.)
Long story short (again, too late!), you might want your regular expression to match these multibyte encodings. Well, the tool can help you — assuming that you’re okay with the most or least significant byte being zero. That’s where this comes into play:
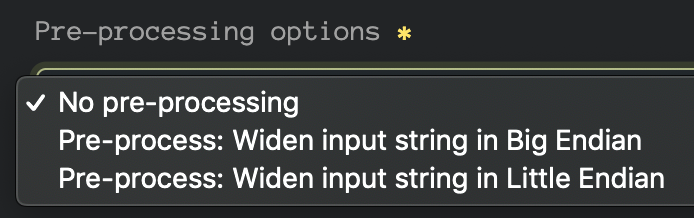 If
If
you want the regular expression ABC to actually match the string Ax00Bx00Cx00 or even x00Ax00Bx00C then you’re in luck! Let’s give it a shot:
curl "https://labs.inquest.net/api/yara/base64re?option=widen_big,instring=ABC"
And here’s what we get: ([x2bx2f-9A-Za-z][AQgw]B{2}AEIAQ[x2bx2f-9w-z]|[x2bx2f-9A-Za-z]{2}[048AEIMQUYcgkosw]AQ{2}BCAE[M-P]|AE{2}AQgBD)
That’s a regular expression that will match the string ABC if it’s in big-endian format. Let’s try it out using the Python trick from above:
>>> import base64
>>> import re
>>> encoded = base64.b64encode(b"x00Ax00Bx00C")
>>> re.match(br"([x2bx2f-9A-Za-z][AQgw]B{2}AEIAQ[x2bx2f-9w-z]|[x2bx2f-9A-Z
a-z]{2}[048AEIMQUYcgkosw]AQ{2}BCAE[M-P]|AE{2}AQgBD)", encoded)
<re.Match object; span=(0, 8), match=b'AEEAQgBD'>Success! Notice the x00 bytes in front of each character in the encoded string (because the “most significant byte” of the regular old character A is 0). Notice that our regular expression matched. (Notice also that I used Python 3 for this example instead of Python 2…)
Followup
The InQuest Labs site is accessible The InQuest Labs site is accessible programmatically via a RESTful API. This includes the Base64 Regular Expression Generator. If you’re interested, we definitely encourage you to try it out.
^1^ This is using the REST-ful API provided by InQuest Labs. In general, the responses will come back as JSON. Certain error messages will start with a “?” in the result. If you play around with the tool, you might find that there’s a tiny Commodore 64 Easter Egg to be found… ^2^ This symbol is more colloquially called “lamp” and it starts the beginning of a comment in the APL programming language. While it’s said “lamp” and looks like a big toe, I think I’m going to start yelling “APLFUNCTIONALSYMBOLUPSHOEJOT” every time I see it.
How Effective Is Your Email Security Stack?
Did you know, 80% of malware is delivered via email? How well do your defenses stand up to today’s emerging malware? Discover how effectively your email provider’s security performs with our Email Attack Simulation. You’ll receive daily reports on threats that bypassed your defenses as well as recommendations for closing the gap. Free of charge for 30 days.
![]()