
SOC analysts typically have access to a mix of proprietary, commercial, open source, and personal reputation sources for various indicator of compromise (IOCs). IOCs include file hashes, IP addresses, domain names, SSL certificate fingerprints and more. Aggregating the variety of feeds into a single source is a prudent first-step for manual search and programmatic accessibility. In this article we outline a number of publicly available resources and describe a simple method for aggregating them into a single reputation database. The final product, while not containing the highest fidelity data, can provide a valuable reference for threat hunters. Commercially, we supply InQuest users with a propriety reputation API, sourced from both manual and automated threat hunting efforts. Over 80% of these artifacts do not overlap with what we’re seeing in the public domain.
Talk to any of our security engineers and you’ll be sure to hear at some point that we “throw everything and the kitchen sink” at the problem of identifying malicious content. We consider a variety of artifacts such as IPs, URLs, HTTP and SMTP headers, and more. Primarily our focus is file centric. Files are carved off the wire, fed through our Deep File Inspection ® (DFI) stack, and then analyzed for signs of malignant code. The DFI process is recursive in nature and allows us to peel away compression, obfuscation, encoding, and layering techniques used by attackers to mask their payloads and ultimately evade detection. Our system functions in parallel in a map-reduce like pattern that results in the output of a single threat score per session, ranging from 0 to 10. The threat scoring algorithm is primarily driven by file-analysis but additional factors can move a score up or down. This includes inputs from Multi-AV providers (OPSWAT, VirusTotal), detonation solutions (Cuckoo, Joe Sandbox, VMRay, FireEye, Falcon aka HybridAnalysis), and a multitude of reputation sources. The variety of sources are highlighted in a “threat receipt”:

Stacking sources under a single pane of glass is valuable to a SOC analyst for determining if any given alert is a true positive or not. Consensus across multiple sources is a solid indication that a threat is legitimate. Conversely, there’s value for threat hunting teams in filtering their alert stream based on these same sources. Consider for example the hunt for targeted attacks. In this case the hunter will want to search for InQuest or internally sourced alerts that do not overlap with known malware (AV hits) or commonly shared endpoints (public reputation). Seeing as how multi-sourcing threat intelligence is valuable in a variety of ways, the rest of the article provides a high level walk-through of the key requirements for creating your own public domain IOC aggregator. First, we’ll begin with available open-source solutions.
OSS or Scrape & Parse?
There are many different tools that can be used to aggregate data from public intelligence feeds and we took a few publicly available ones for a test drive. We looked at CIF, its successor Bearded Avenger (CIF v3), YETI, and have our own horse in the race: The OSINT Omnibus. CIF and Bearded Avenger are commonly used tools for gathering threat intelligence that allow you to combine data from numerous public feeds, and your own data. YETI is another aggregation tool with a feature rich UI and storing the data in a NoSQL format. Any of these tools could be be great depending on your specific use-case. If nothing quite fits the bill however, it’s trivial to build your own programmatic scraper or even lean on staple tools such as wget and curl. The trickier portion is extracting the indicators you’re interested in.
The majority of the parsing is done via regular expressions (regex). The regex for extracting an IP, hash, and ASN are fairly trivial. URLs on the other hand can be quite a handful to get right. Let’s lean on a well maintained and ever evolving community effort, Gruber Liberal Regex Pattern for Web URLs:
# not so easy.
URL_RE = (?i)b((?:https?:(?:/{1,3}|[a-z0-9%])|[a-z0-9.-]+[.](?:com|net|org|edu|gov|mil|aero|asia|biz|cat|coop|info|int|jobs|mobi|museum|name|post|pro|tel|travel|xxx|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cs|cu|cv|cx|cy|cz|dd|de|dj|dk|dm|do|dz|ec|ee|eg|eh|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|Ja|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw)/)(?:[^s()<>{}[]]+|([^s()]*?([^s()]+)[^s()]*?)|([^s]+?))+(?:([^s()]*?([^s()]+)[^s()]*?)|([^s]+?)|[^s`!()[]{};:'".,<>?])|(?:(?<!@)[a-z0-9]+(?:[.-][a-z0-9]+)*[.](?:com|net|org|edu|gov|mil|aero|asia|biz|cat|coop|info|int|jobs|mobi|museum|name|post|pro|tel|travel|xxx|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cs|cu|cv|cx|cy|cz|dd|de|dj|dk|dm|do|dz|ec|ee|eg|eh|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|Ja|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw)b/?(?!@)))
# easy.
IP_RE = (d{1,3}.d{1,3}.d{1,3}.d{1,3}(?:/d{1,3})?)
DOMAIN_RE = [w-.]+[^.s/d]{2,}
ASN_NUM_RE = b(AS[d]{1,10})(?=.;.)b
Alternatively, you can outsource IOC extraction to python-iocextract (readme), an open-source and open-licensed library we wrote and maintain. With our regular expressions in hand, let’s take a look at the sources we’ll be scraping.
Sources
As of the time of writing, we’ve enumerated 44 publicly available feeds across 22 unique sources. If we’ve missed any, be sure to let us know via e-mail or Twitter. Reputation data is time sensitive. While some indicators can last for years, others can cycle from malicious to benign in the same. As a recommended default, consider expiring any scraped artifacts after 30 days. On an anecdotal side note, we have some proprietary entries in our reputation feed that go back to 2014 … and we still see them in use periodically. Some malicious actors will cycle through their available infrastructure.
Consider the following table:
| Source | Data Type | Update Rate | Description |
|---|---|---|---|
| Alienvault | IP | 6hr | AlienVault IP reputation database |
| Bambenek | IP | 1hr | Bambenek Consulting feed of C2 IP addresses |
| BinaryDefence* | IP | 12hr | Binary Defence Systems IP addresses from threat intelligence and banlist feeds |
| Blocklist | IP | 3hr | Blocklist IP addresses reported for running attacks by users primarily using fail2ban |
| Botscout | IP | 3hr | Botscout IP addresses of bots |
| Bruteforceblocker | IP | 12hr | Bruteforceblocker IP addresses from users reporting failed authentication attempts |
| Ciarmy | IP | 24hr | CIArmy IP addresses that they score poorly and are not yet widely identified as being malicious |
| Csirtg | IP | 1hr | CSIRTG IPv4 Addresses seen delivering unsolicited commercial emails |
| Cybercrime | IP | 3hr | Cybercrime IP addresses tracking C2 |
| Dataplane | IP | 3hr | Dataplane IP addesses that have been seen doing various attacks |
| Feodo | IP | 3hr | Feodo IP addresses used as C2 communitcation channel by the Fendo Trojan |
| Isc.sans* | Domain | 3hr | Isc.sans domains collected from dshield.org |
| Malc0de | IP | 12hr | Malc0de IP addresses recently caught distributing malware |
| Malwaredomainlist | IP, Domain | 12hr | Malwaredomainlist IP addresses and domains that are actively malicious |
| Openphish** | URL | 12hr | OpenPhish URLs found using AI algorithms to find zero-day phishing sites |
| Packetmail* | IP | 12hr | Packetmail IP addresses found performing TCP SYN to non-listening service |
| Phishtank | URL | 24hr | Phishtank URLs used in phishing campaigns |
| Spamhaus | ASN | 8hr | Spamhaus list of ASNs known to be run by spammers, ASNs run by cyber criminals, and highjacked ASNs |
| Sslbl** | IP | 3hr | SSLBL Hashes associated with malicious SSL certificates |
| Talos Inteligence | IP | 12hr | Talos Intelligence IP addresses of known network threats flagged on all Cisco Security Products |
| Threatweb | IP, Domain, URL | 3hr | Threatweb lists of malicious domains, malicious IPs, malicious URLs, and botnet IPs |
| VxVault | IP. URL | 12hr | VxVault list of malicious URLs and their IPs |
| IP, Domain | 3hr | Zeus IP addresses and domains used by the ZeuS trojan |
* denotes not licensed for commercial use
** denotes user must contact owner of list for commercial use
The Source, Data Type, and Description columns in the table are self explanatory. The Update Rate represents the recommended amount of time to wait between scrapes of that specific source. This recommendation is based on the rate at which the source updates their data, but it is not exactly the same. Scraping these sources over the course of a few days will result in an artifact extraction rate like so:
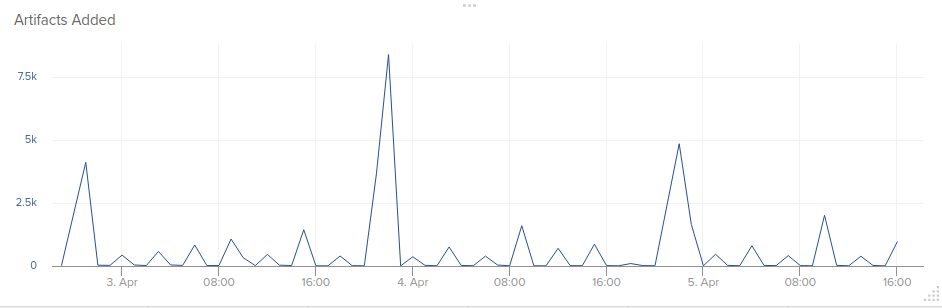
Artifacts such IP, domain, hash, URL, and ASN are all directly available from the sources above. You can take a step further though and alongside the primary data type, extrude derived information as well. Consider for example, resolving the ASN for every IP and building a reputation score per ASN sourced on the number of malicious IPs it contains. Using the ASN data
from MaxMind, one can calculate the ratio of known malicious IPs out of the total number of IPs under the given ASN. Depending on your tolerance, if a threshold is exceeded, you may consider blocking or alerting on any communications with any IP address under the ASN.
As an exercise, we implemented the above at a 5% threshold, producing the following table as of the time of writing (April 2018):
Count = amount of unique suspicious IPs
Total = total amount of possible IPs in the ASN
Percentage = count / total * 100
| ASN Number | ASN Name | Count | Total | Percentage |
|---|---|---|---|---|
| 42570 | Nagravision SA | 289 | 512 | 56.44 |
| 35828 | Teratrade Hungary Kft | 517 | 1280 | 40.39 |
| 63128 | Strong Technology | 517 | 1280 | 40.39 |
| 48131 | EAN NUM LOG Kft. | 374 | 1024 | 36.52 |
| 52635 | TECNOLOGIA E EQUIPAMENTOS | 286 | 1024 | 27.93 |
| 199264 | Estro Web Services Private Limited | 138 | 768 | 17.96 |
| 64484 | Jupiter 25 Limited | 36 | 256 | 14.06 |
| 58222 | Solar Invest UK LTD. | 56 | 512 | 10.93 |
| 57509 | L&L Investment Ltd. | 26 | 256 | 10.15 |
| 205092 | Outsource Grid Limited | 24 | 256 | 9.37 |
| 264643 | Enredes S.A. | 87 | 1024 | 8.49 |
| 206791 | Slobozhenyuk B.Y. PE | 21 | 256 | 8.20 |
| 39517 | Hostmaze Inc Srl-d | 21 | 256 | 8.20 |
| 263368 | CASA DA INFORMATICA LTDA – ME | 161 | 2048 | 7.86 |
| 205280 | United Protection (UK) Security LIMITED | 19 | 256 | 7.42 |
| 43765 | Pp Sks-lugan | 70 | 1024 | 6.83 |
| 60307 | FOP HORBAN VITALII Anatoliyovich | 17 | 256 | 6.64 |
| 202963 | Master-Integration Ltd | 16 | 256 | 6.25 |
| 262812 | K.H.D. SILVESTRI E CIA LTDA | 314 | 5120 | 6.13 |
| 263880 | WANTEL TECNOLOGIA LTDA. Â EPP | 245 | 4096 | 5.98 |
| 394380 | Leaseweb USA | 777 | 14080 | 5.51 |
| 262711 | TEK TURBO PROVEDOR DE INTERNET LTDA | 426 | 8192 | 5.20 |
When determining whether or not an artifact is malicious, it is critical to have as much supporting information as possible to make that determination. An aggregated reputation database containing data from reliable intelligence sources provides a great analytical layer of scrutiny that can be used to identify suspicious and/or malicious content within your environment.
Resources
- OSINT Omnibus
- FireHOL: Good source of different IP feeds, and a large amount of interesting data for each feed.
(Website, Source list) - YETI: Premade reputation aggregator and database (Website, Repository)
- CIF: Premade reputation aggregator and database (Website, Repository)
References
- http://csirtgadgets.org/collective-intelligence-framework
- https://github.com/csirtgadgets/bearded-avenger
- https://github.com/yeti-platform/yeti
- https://gist.github.com/gruber/8891611
- https://www.alienvault.com/
- http://osint.bambenekconsulting.com/feeds/
- https://www.binarydefense.com/banlist.txt
- https://lists.blocklist.de/lists/
- http://botscout.com/
- http://danger.rulez.sk/
- http://www.cinsscore.com/
- https://csirtg.io/users/csirtgadgets/feeds
- http://cybercrime-tracker.net/
- https://dataplane.org/
- https://feodotracker.abuse.ch/
- https://isc.sans.edu/
- http://malc0de.com/dashboard/
- http://www.malwaredomainlist.com/
- https://openphish.com/
- http://cdn.miscreantpunchers.net/iprep.txt
- https://www.spamhaus.org/
- https://sslbl.abuse.ch/blacklist
- https://www.talosintelligence.com/
- https://www.threatweb.com/access/
- http://vxvault.net/ViriList.php
https://zeustracker.abuse.ch/*Discontinued 2019- https://dev.maxmind.com/geoip/geoip2/geolite2/
- https://iplists.firehol.org/
- https://github.com/firehol/blocklist-ipsets
- https://yeti-platform.github.io/
- https://github.com/csirtgadgets/massive-octo-spice
How Effective Is Your Email Security Stack?
Did you know, 80% of malware is delivered via email? How well do your defenses stand up to today’s emerging malware? Discover how effectively your email provider’s security performs with our Email Attack Simulation. You’ll receive daily reports on threats that bypassed your defenses as well as recommendations for closing the gap. Free of charge for 30 days.
![]()